
2023-7-9 arXiv roundup: LLMs ignore the middle of their context, MoE + instruction tuning rocks

This newsletter made possible by MosaicML.
A mini-announcement
Because it’s gotten increasingly difficult to find technical ML content in all the AI noise, I hereby announce a new (experimental) policy:
If you write a Twitter thread explaining a paper, tag me in the thread and I'll retweet it.1
Thread retweet requirements:
4+ posts with (figure, explanation) pairs
Legible figures, good English
Clear articulation of a takeaway, including when it applies + caveats
Empirical results of interest to wide ML audience; e.g., LLMs, BERTs, common CV tasks, efficiency
Hopefully this will make it easier for all of us to find more quality content + for authors to get their work seen.
Lost in the Middle: How Language Models Use Long Contexts
For tasks like multi-document question answering, LLMs do way better if the relevant information is at the beginning or the end of their context.

This result holds for a variety of models and context lengths.

To make this concrete, here’s an example of how they systematically varied the length of the context and placement of the relevant info within it.

If you train the model with a certain number of documents in the context, it’s decent at using the middle when the input is at most that length (leftmost subplot). But when you move past that, inattention to the middle resumes.

Instruction tuning might reduce middle-inattention, but doesn’t eliminate it.

Ignoring the middle probably also caps the benefits of retrieval augmentation. Retrieval recall keeps going up as you retrieve more results, but model accuracy doesn’t.

This is great. Clean, thorough results to add to the ol’ mental model of what’s going on in your neural net.
Mixture-of-Experts Meets Instruction Tuning:A Winning Combination for Large Language Models
They compare MoE models and FLOP-matched dense models across three cases:
Just finetuning on downstream tasks.
Instruction tuning and then in-context learning on downstream tasks.
Instruction tuning and then finetuning on downstream tasks.
MoE models often do worse in the first case, but better in the latter two (where there’s instruction tuning). Interestingly, MoE models also benefit more from instruction tuning than dense ones; usually you see at most additive benefits from composing techniques, so this is surprising. In the below figures, FLAN = instruction tuning.


Provable Robust Watermarking for AI-Generated Text
They divide tokens into a green list and a red list and disproportionately generate from the green list like previous work. However, in this case, they don’t bother with a rolling hash or anything to update the green list; they just fix it based on a random seed at the start.

The advantage of this is that, even if someone paraphrases the text, you can still (provably) detect the watermark under mild conditions—namely, that a disproportionate number of tokens still come from the green list rather than the red list.

In practice, this method works better than existing alternatives that try to vary the green and red lists throughout the document.



Asymptotically, I would expect an attacker to be able to recover the green and red lists as the document length grows with this approach…but I’m not sure this matters? If each document gets a different PRNG seed, this should only let you rewrite that document. So maybe we can’t trust this for watermarking a whole book, but I wouldn’t be surprised if it’s fine for reasonable generation lengths. And even for a book, maybe we just artificially split it into different documents.
What I’m really unsure about is how the random seed gets associated with a document. If one seed is shared across many documents, attackers could recover the lists and generate their own documents. But if it’s tied to a particular document…how do we know which seed was used (so that we can check for the watermark)?
Rockmate: an Efficient, Fast, Automatic and Generic Tool for Re-materialization in PyTorch
They devise an algorithm for determining which activations in your neural net to save vs recompute when doing activation rematerialization. Their algorithm comes up with schemes about as good as Checkmate (a fancy algorithm for this), but does so much more quickly.

The key idea is to come up with a rematerialization plan faster by reusing the block structure present in many common models. You can find good strategies for each block and then figure out the best way to chain the blocks together.


Probably worth trying out their code if you’re hitting RAM issues and don’t know a priori how to configure your rematerialization. Or if you just want the rematerialization done automatically.
Jailbroken: How Does LLM Safety Training Fail?
They use a bunch of jailbreak methods to try to get around the ChatGPT, GPT-4, and Claude content filters.

They measure the efficacy of these attacks across a variety of prompts.

They argue that a lot of the reason jailbreaks work is that big text models:
Are trained on competing objectives, including next-token prediction, instruction following, and alignment with the creator’s refusal-to-answer policies.
The pretraining dataset covers far more material than the safety training dataset; this means there are many things the model knows how to do that it was never taught not to do.
An illustration of the former is “Refusal suppression,” where you try to get the instruction following to override the content filtering.

An illustration of the latter is using Base64 to encode your prompt. The model learns to understand Base64 from pretraining but (probably?) none of the content filtering training data was written this way.

Definitely the most thorough roundup of jailbreaking techniques + analysis that I’ve seen.
Focused Transformer: Contrastive Training for Context Scaling
They messed with the training procedure for every 4th attention layer and added retrieval augmentation at test time to enable finetuned OpenLLaMA models to handle super long contexts.
The core idea here is that attention layers get “distracted” by irrelevant tokens in long contexts. If you add d documents to the context, the attention allocated to each of them will have magnitude proportional to 1/d by default. Their method lifts this a ton to disproportionately attend to the current or most relevant document.

They help the model block out extraneous kv pairs in the context by adding a contrastive loss. This loss encourages the queries to have larger inner products with keys from their own document than other documents in the batch.
This apparently spreads out the keys and values way better in their high-dimensional space, letting their improved models crush synthetic tasks like dictionary lookups—even with context lengths in the millions.

At test time, the layers that were trained this way get access to an external memory, consisting of previous KV pairs (think Memorizing Transformer). At least when using exact nearest neighbor search, this overall scheme can improve model quality significantly across various downstream tasks.

We’ve seen in the information retrieval literature that using a contrastive loss can help a lot, so the fact that it helps retrieval-augmented models isn’t super surprising. However, the magnitude of the improvement on synthetic tasks is so large that it makes me suspect our default key and value vectors are terrible for retrieval. Maybe another pathology of self-attention we need to diagnose and fix?
Improving Retrieval-Augmented Large Language Models via Data Importance Learning
One of the classic ways to improve the speed and accuracy of knn models is to intelligently prune the dataset they’re searching over. Can we get this to work for retrieval-augmented text models?

Yes, but…it’s hard. With a knn model, it’s easy to understand which points in your database contribute to which predictions, and what would happen if you removed them. But when sets of documents from your database get fed through a neural net together, attribution is a tough problem.
To solve this problem, they frame it in terms of learning weights for different documents, with the loss treated as a set function whose inputs are subsets of documents.

Adding retrieval with their pruned corpus can lift accuracy a lot both for GPT-JT and GPT-3.5.

The accuracy lifts are so large that a 6B param retrieval-augmented model can often outperform the 175B param GPT-3.5 without retrieval.

Pretty impressive accuracy lifts, suggesting that database pruning for retrieval-augmented models is promising—especially since we’ve already seen small, high-quality datasets work super well for language model training. If anything, data filtering might be more promising in the retrieval case since you get a direct training and inference speedup, on top of the model quality gains.
Multi-Similarity Contrastive Learning
What if you want to do contrastive learning but you have multiple notions of similarity that you want to capture in your embeddings? Turns out just adding a per-similarity-metric head to the encoder and training them all jointly works pretty well. You can also weight them differently based on how much you care or are certain about the different similarity measurements.

This can often yield better representations, both in-distribution and out-of-distribution.


What’s especially cool is that it generalizes to held-out similarity measures, not just distributions.

Might a fairly general win for contrastive training.
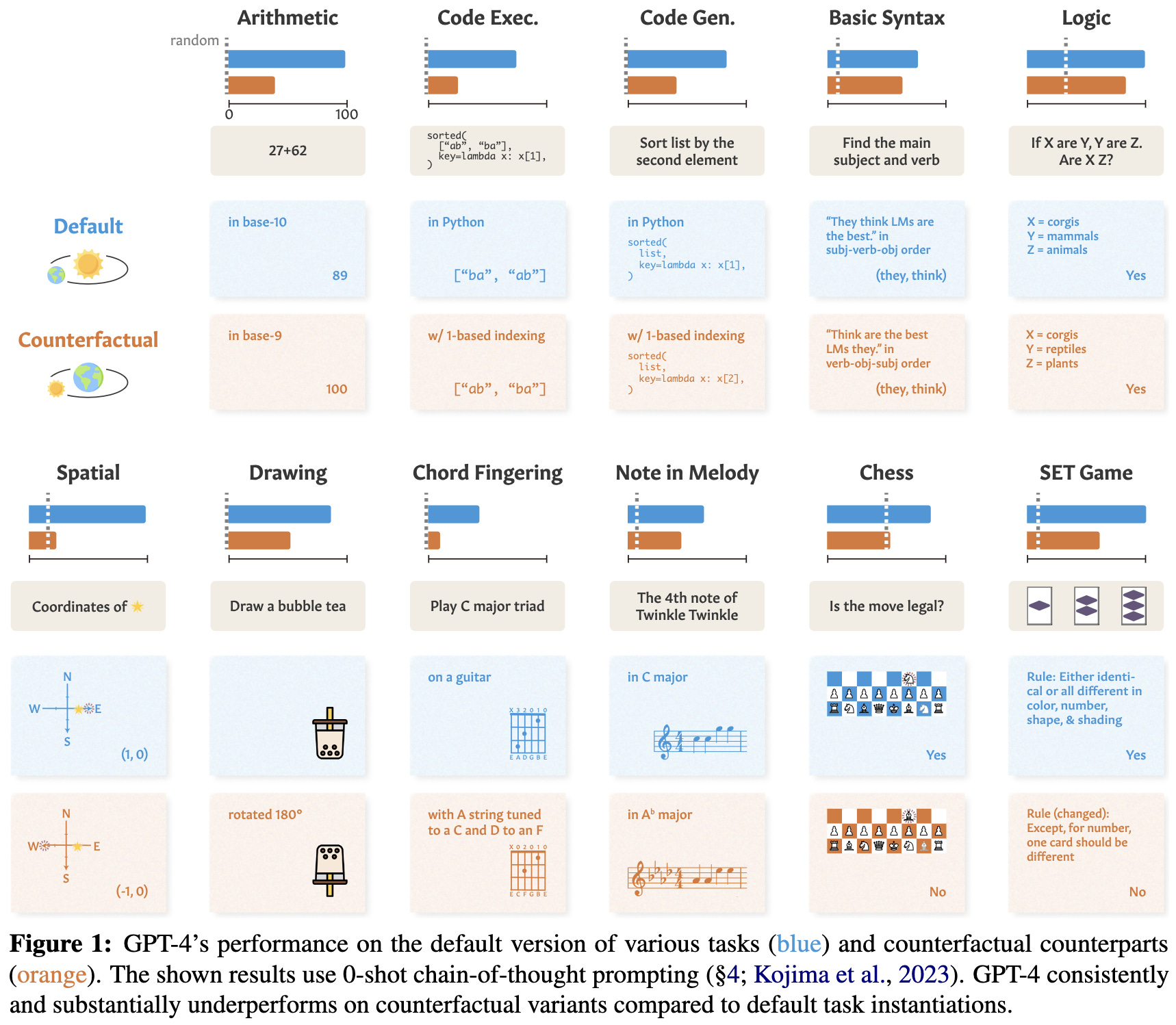
Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks
LLMs are better at reasoning and task solving when the structure of the task matches their training data—as opposed to being abstract reasoners that bind symbols, run logical inference, etc. You can tell because they’re consistently worse at counterfactual versions of tasks, which roughly preserve the logical structure but change the semantics.

The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks
Do neural nets consistently learn the same approach to solving simple tasks? Nope. For modular addition, they often learn the simple + interpretable “Clock” algorithm, but sometimes learn other approaches like the novel “Pizza” algorithm.

Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing
Are there consistent, interpretable differences in the behavior of CNNs and ViTs when holding image classification accuracy roughly constant?

Yes. Besides the known differences in shift invariance, ViTs are way better at ignoring irrelevant image patches.

However, if you do data augmentation to teach models to ignore irrelevant patches during training, CNNs can mostly close the gap.

Seems like a clear indication of ViT inductive biases / structural priors helping. If a difference that
a) appears in the absence of supervision, but
b) goes away given enough supervision
isn’t a “structural prior”, I’m not sure what is.
Self-Consuming Generative Models Go MAD
What happens when you iteratively train image generation models on their own outputs?
Bad things.

This isn’t just a toy problem. People are putting more and more AI-generated images on the internet, so future web scrapes will end up training on this data even if they don’t want to.

The paper considers three cases: training purely on generated images, training on a fixed real dataset + generated images, and training on a new pool of real and generated images each time.

When generated images dominate, you end up losing either generation quality or diversity over time.

Having a fixed dataset of real images alongside the generations can let you hold out for more cycles, but doesn’t fix the problem.

If you’re constantly getting both real and generated images, there’s a bias-variance tradeoff. When you have too few real images, adding generated images can help. But once you have enough real images, adding generated ones only hurts. Interestingly, this seems to be an absolute threshold, not a matter of the ratio between the two.

So…not looking good for the quality of future image generation models as the number of generated images grows. We could be at peak data internet quality right now.
Relatedly, we might end up building deepfake detectors not just for societal purposes, but also to filter our training data. This bodes well—more economic incentive to solve this problem sounds like a good thing.
A couple caveats:
I don’t necessarily log into Twitter in a given day (or…week) so this is a general policy, not a promise
I’m hoping the requirements I laid out are enough to ensure quality content, but I might amend them or just cancel this policy. This is to avoid the terrible situation where content meets the requirements but is below the bar in terms of quality or relevance; this forces me to choose between saying no to authors and wasting followers’ attention, which is a no-win choice.
Please don’t read anything into whether I retweet or quote tweet. This is mostly a function of whether I think I can say a couple sentences that add value + have a few spare minutes to write something.