
2023-8 arXiv roundup: Look I gave a talk, SILO-ing language models, lots of MoE + tool use papers

(I’m still planning on doing weekly installments in general—I just got behind and it took a while to catch up).
This newsletter made possible by MosaicML. Speaking of which, I gave a talk about our journey as a company on Aleksa Gordic’s Discord:
Turns out we’re the 2nd fastest zero-to-billion-dollar-acquisition ever (after Instagram).1 Obviously tons of luck and market timing involved, but hopefully there are some useful lessons here too.
Side note: this was a lot of fun and I’d be down to talk about Mosaic, LLMs, AI startups, etc, if anyone else out there is looking for guests/speakers.
From Sparse to Soft Mixtures of Experts
Instead of having hard assignments of tokens to experts, they feed linear combinations of all tokens to each expert. This works for vision tasks where you aren’t worried about causal dependencies between tokens.
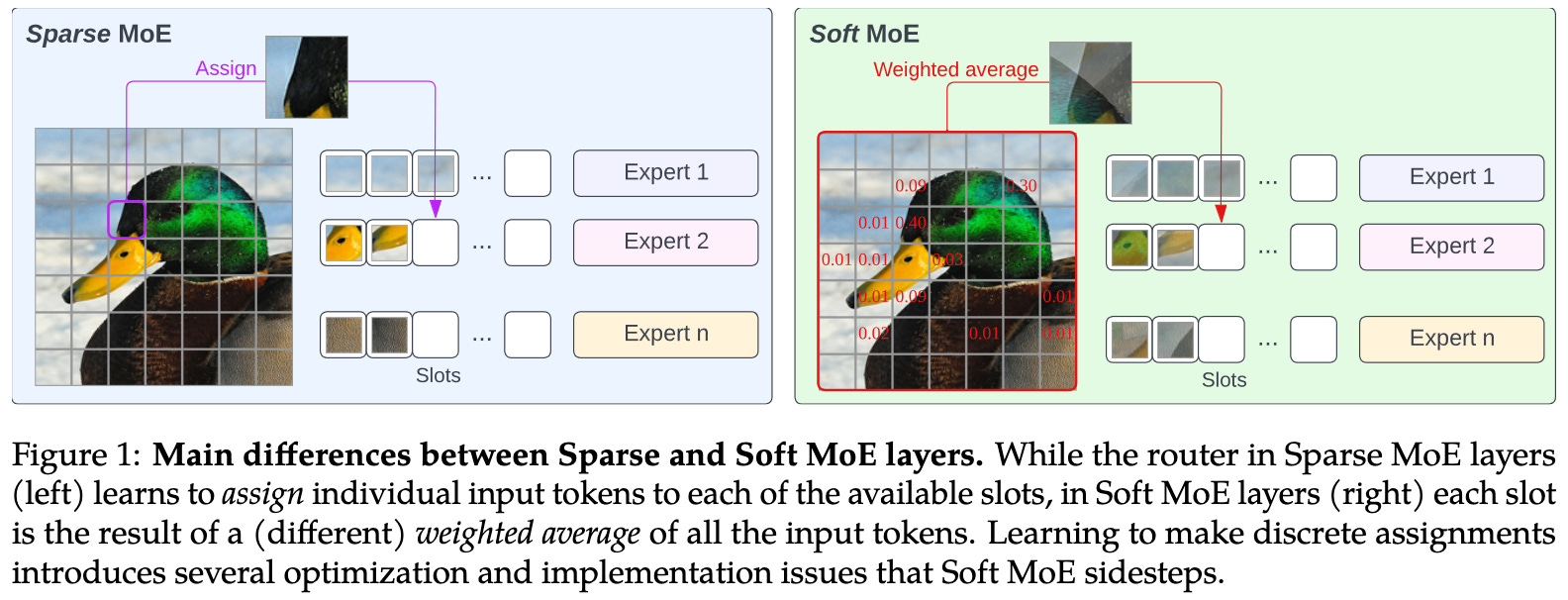
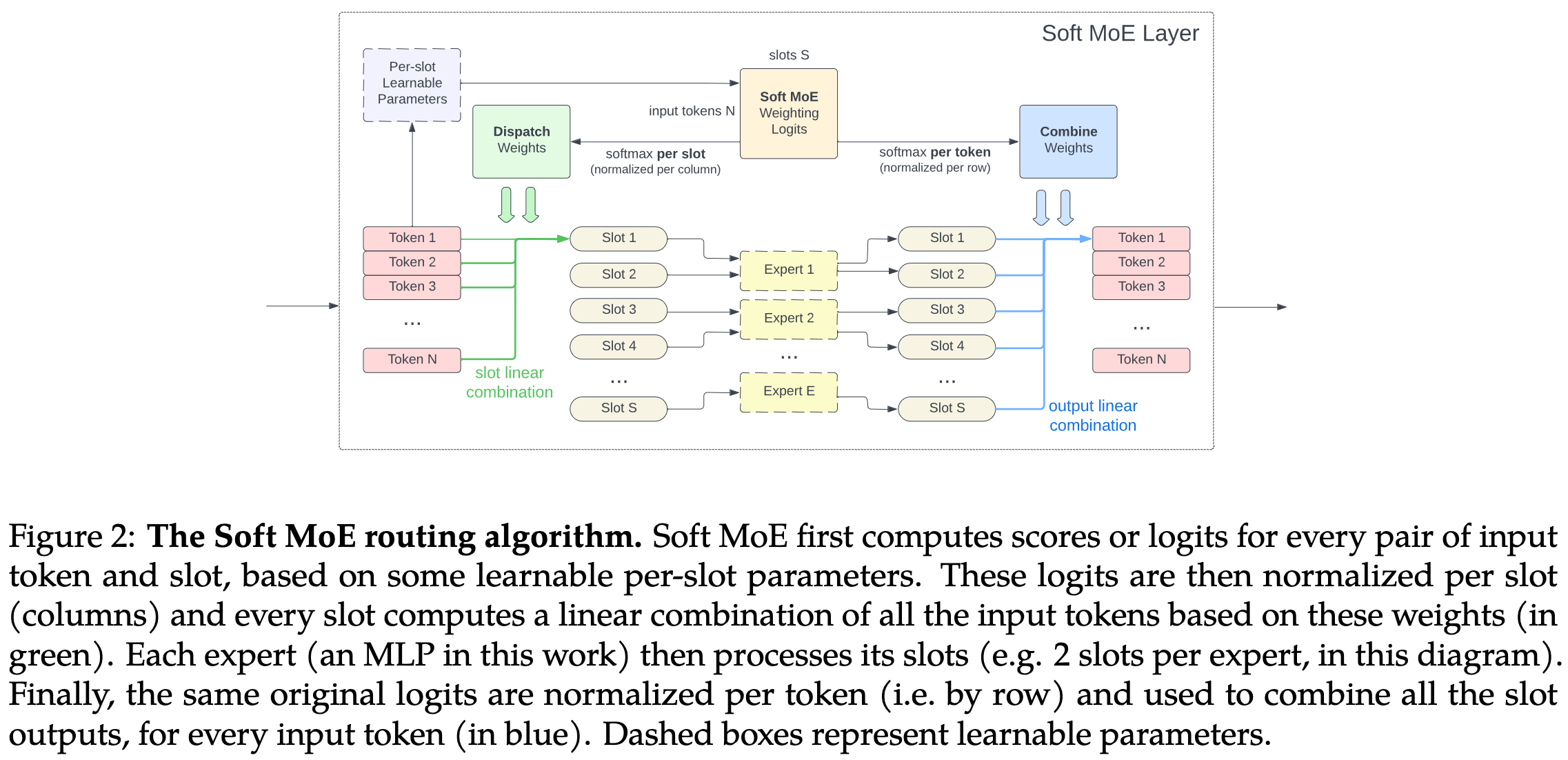
This approach seems to work a lot better than regular Top-K or expert-choice routing when holding training or inference time constant.

They also show that their approach can improve inference speed significantly compared to baseline dense models.
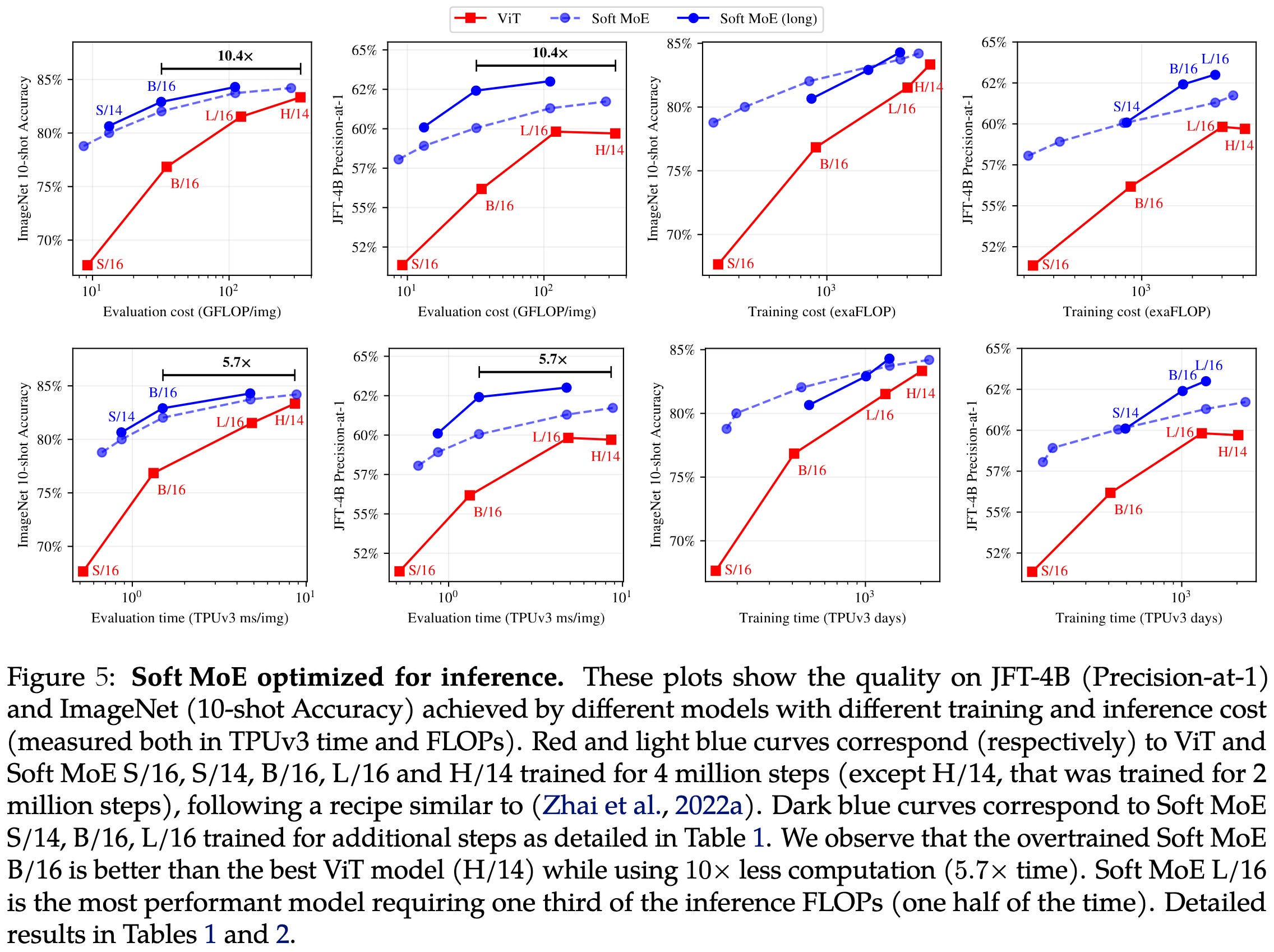
Seems like a significant win when you don’t need causal decoding—especially since this method also avoids the load imbalance and test-time nondeterminism of typical MoE approaches.
SILO Language Models: Isolating Legal Risk In a Nonparametric Datastore
People sometimes don’t like when you train models on their content. But no one seems to mind when search engines surface snippets of their content. So the idea here is to train the model only on permissively-licensed documents and add a retrieval system that searches over the rest of the documents at test time.
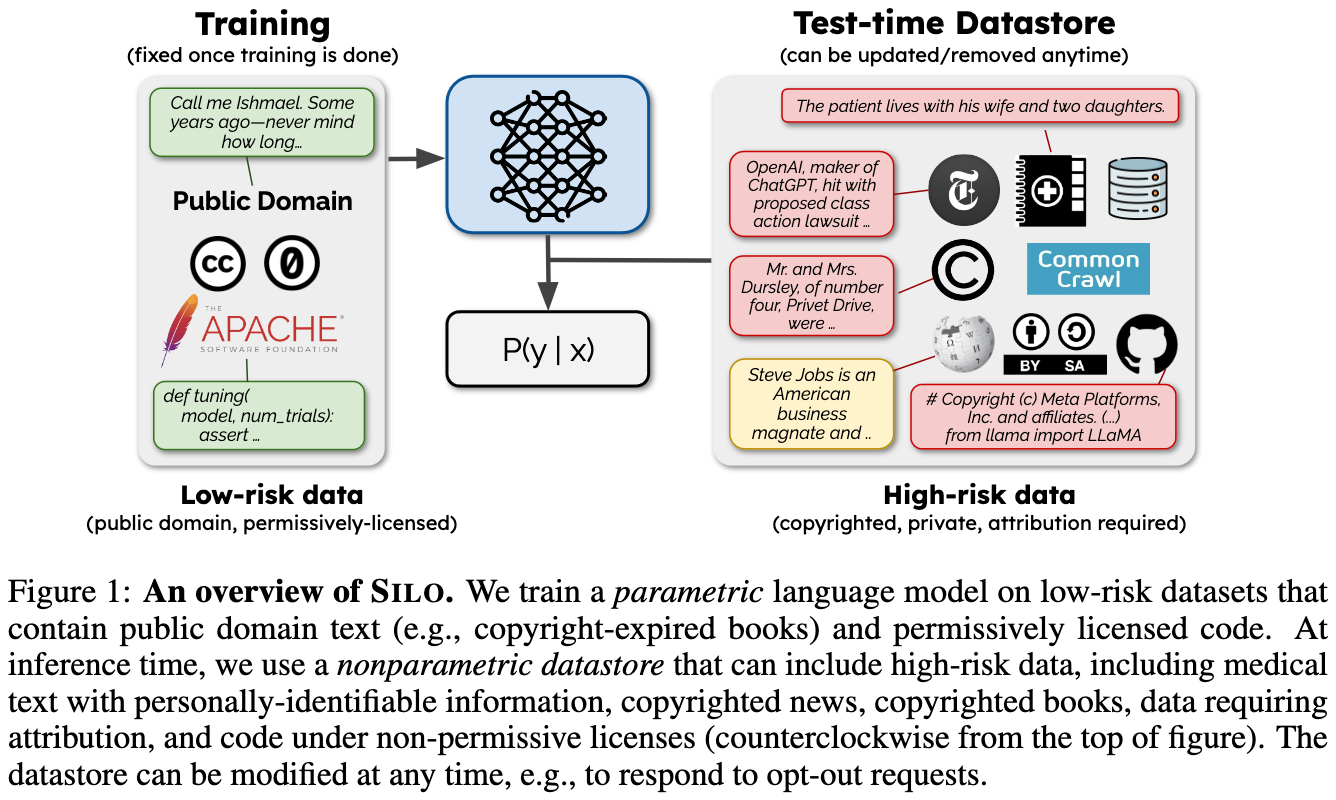
First, they did a breakdown of how content is licensed for different datasets. There are a lot of public domain books, legal documents, and arXiv abstracts, but not much else.

As you’d expect, training on the small, permissively-licensed subsets yields much higher perplexities than just training on everything (right column).

However, if you retrieve relevant documents using kNN-LM, you can sometimes close the gap.

Encouragingly, larger retrieval datasets yield lower perplexities. This suggests that scaling up the retrieval could improve outputs further.

The gap from not training on all the data is probably much larger than you’d guess from this; this is because, normally, retrieval-augmentation does way better than the baseline. But this approach still seems like an elegant idea that I could totally see becoming standard if copyright case law goes a certain way.
Generating Image-Specific Text Improves Fine-grained Image Classification
Consistent with what we’ve seen previously, they find that using a captioning model to generate better captions for CLIP works really well. This is especially true for fine-grained classification; e.g., a generic description of a bird won’t help us much as a species-specific description.
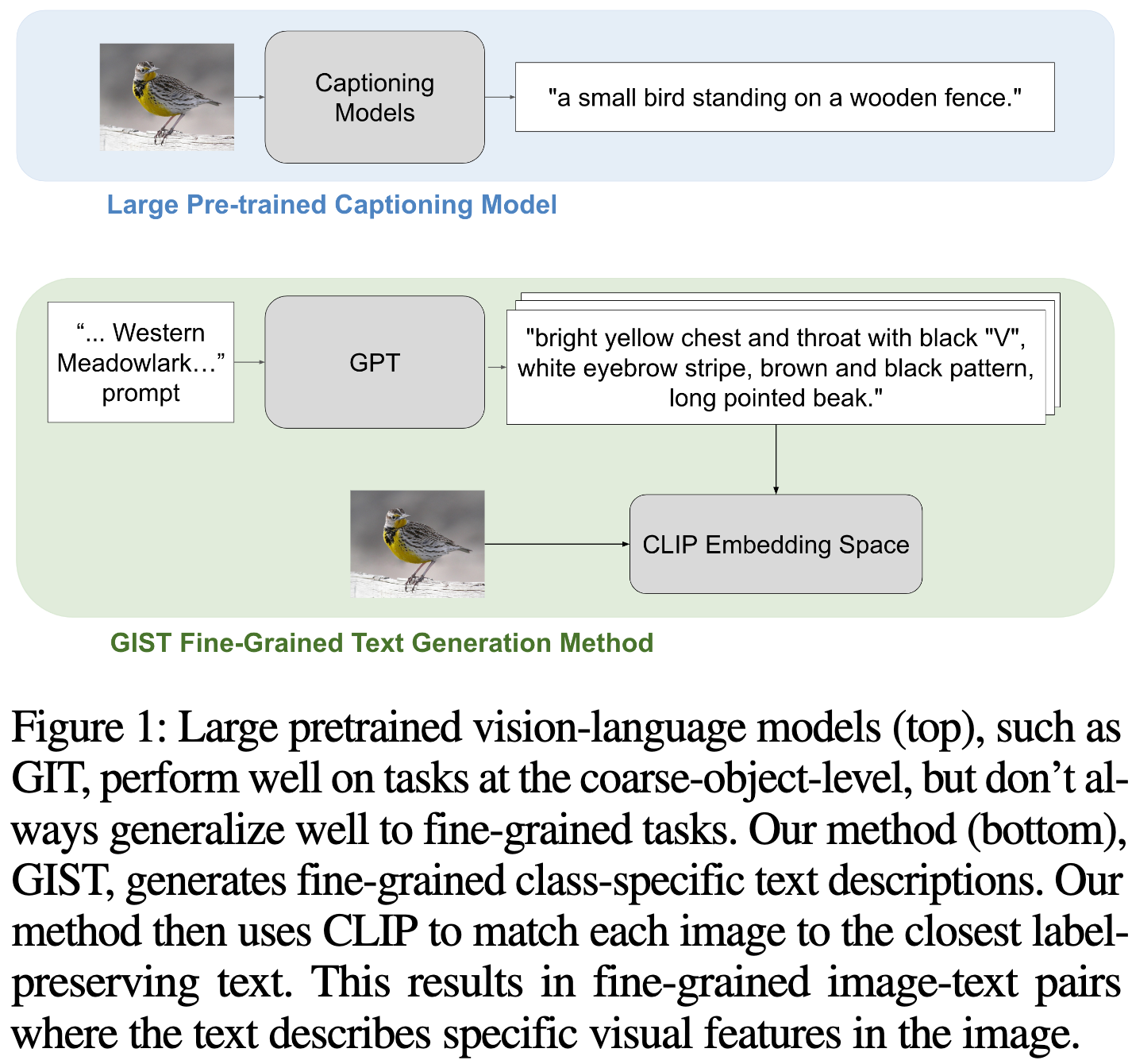
More precisely, they propose a pipeline that generates candidate descriptions for a given class, picks a subset of these captions that already align well with a given image, and then combines these captions into a single image-specific caption. All of this uses an off-the-shelf LLM + CLIP model.

Given the image-caption pairs, they finetune both the image and text encoders in the CLIP model. They then freeze this model and train an image classifier on the CLIP image embeddings.
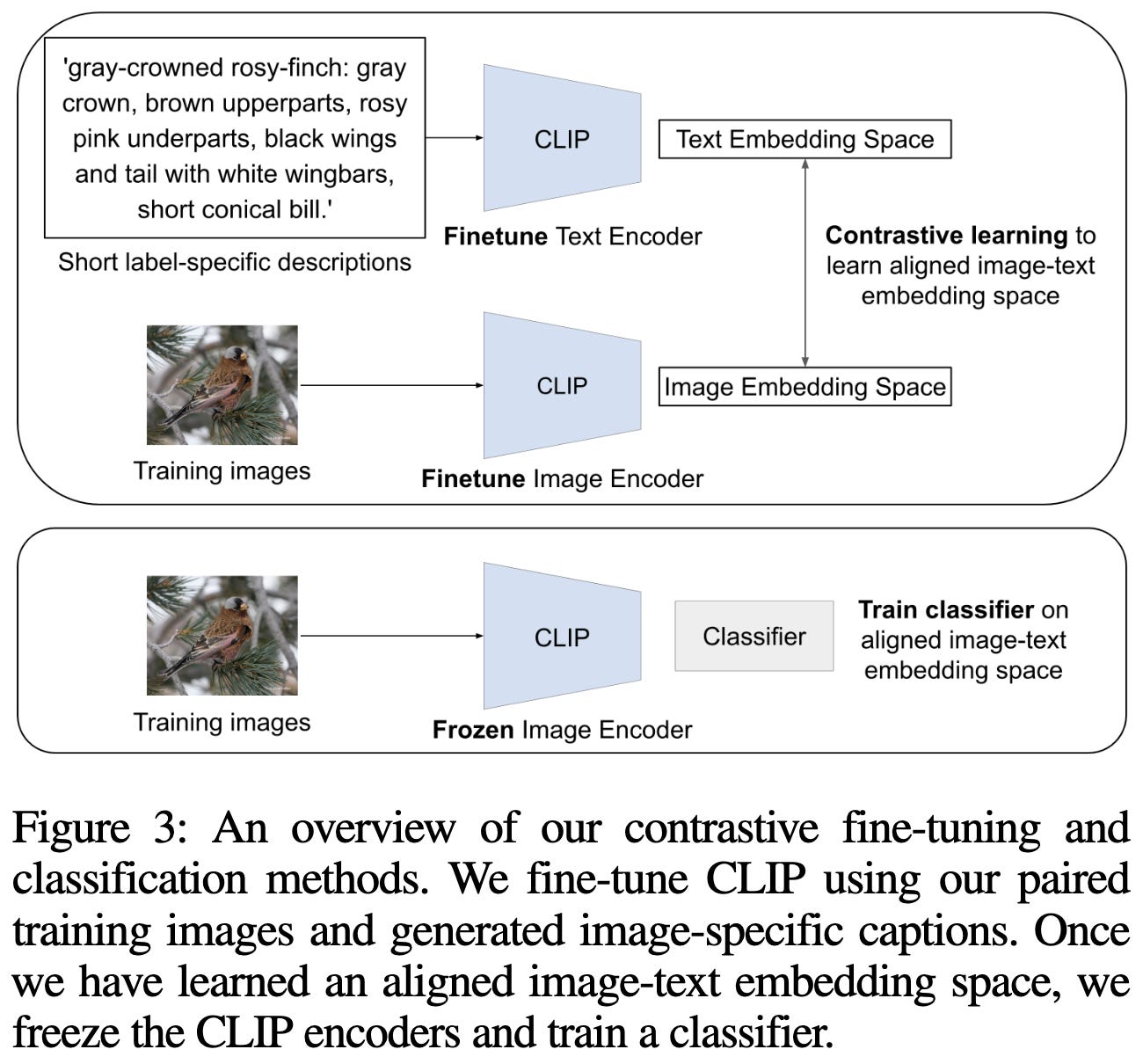
This pipeline often generates more concise and relevant captions than various alternatives.

In controlled experiments, this method yields higher downstream accuracy than various baselines for a number of fine-grained image classification tasks.


Another nice example of using models to generate training data.
Universal Majorization-Minimization Algorithms
The high-level approach to optimization that we always think about in deep learning is Taylor approximation. We look at the gradients (1st order), maybe approximate the Hessian (2nd order), and use these to descend on our loss surface.
An alternative approach is majorization-minimization (MM). The idea here is to upper bound our loss—with the upper bound tight at the current point—and then jump to a lower point on this upper bound. Think Expectation Maximization, K-means, variational lower bounds, etc.

Normally you need to invent an upper bound for a given function by hand, which is hard. They devised a method to instead automatically formulate an upper bound for any function that’s made up of additions, multiplications, and common nonlinearities. The upper bound only holds in a local trust region though.

Using this upper bounding subroutine, they introduce a method to optimize multivariate functions such that the every iterate is guaranteed to obtain lower training loss than the last.

It does require extra forward passes, but has pretty interesting theoretical guarantees.


It’s not clear yet how well it works in practice, but they do show that you can use it to automatically set step sizes with existing optimizers on small neural nets.

Mostly I like this because it expanded my thinking about deep learning optimization. We tend to take the gradient + Hessian approximation approach for granted, but this made me wonder if majorization-minimization has a bunch of untapped potential.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
A clear, well-organized paper that discusses different challenges associated with RLHF. In particular, it distinguishes between technical challenges that we might be able to solve and more fundamental challenges with this class of method.


Fundamental RLHF challenges:
Humans struggle to objectively evaluate performance on many tasks. E.g., you might not spot security vulnerabilities in LLM-generated code.
Humans can be misled / their evals can be gamed.
More detailed supervision takes more effort to provide
Human values are hard to represent as reward functions
Different humans have different values
Reward hacking is possible unless somehow your reward model lines up perfectly with what you want
Test-time distribution shift is a thing
Power-seeking / instrumental convergence
Tractable RLHF challenges:
Getting representative, non-malicious humans
Human labeling errors
Sampling bias in what data gets labeled (e.g., who knows what end user traits correlate with choosing to label your ChatGPT conversations)
Shortcut learning in the reward model
Evaluating reward models well
Adversarial inputs (think ChatGPT jailbreaks)
RL is hard and brittle, especially when you’re training the reward model and policy together.
We shrink towards the pretrained model during RLHF, and who knows what weird behavior that model learned from the internet
They also discuss a number of strategies for dealing with these challenges,

as well as how one might go about auditing an RLHF system.

This paper managed to be both detailed and easy to understand, which is great.
Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models
They propose a curriculum learning strategy based on offline analysis of different “skills” a model can learn and the dependencies between these skills.

The first interesting finding here is that interpretable “skills” seem to be a real thing sometimes. E.g., training on {English, Spanish question answering} first can improve Spanish question generation; and do so even more than just training on Spanish question generation from the outset.

To formalize this curriculum learning problem, they consider the setting where you’re given a set of training and eval “skills,” each associated with a set of samples. They seek to a) construct a graph of dependencies between these skills and b) use this graph to intelligently choose samples throughout training (i.e., do curriculum learning).

To learn the graph, they basically just train a lot of models and add an edge between skills A and B if training on A first reduces the loss on B.

Given the graph, they sample from the data for different skills based on the losses for all the eval tasks and how each training skill affects them.

These time-varying curricula improve the training steps vs time tradeoff across a variety of tasks.

Seems like a promising data selection / curriculum learning approach, and also suggests that maybe we can decompose LLM capabilities into meaningful + interpretable chunks.
Tool Documentation Enables Zero-Shot Tool-Usage with Large Language Models
People often try to get LLMs to call external APIs when needed. Usually, to help the model do this, you provide in-context examples of how to call the API and what the outputs look like.
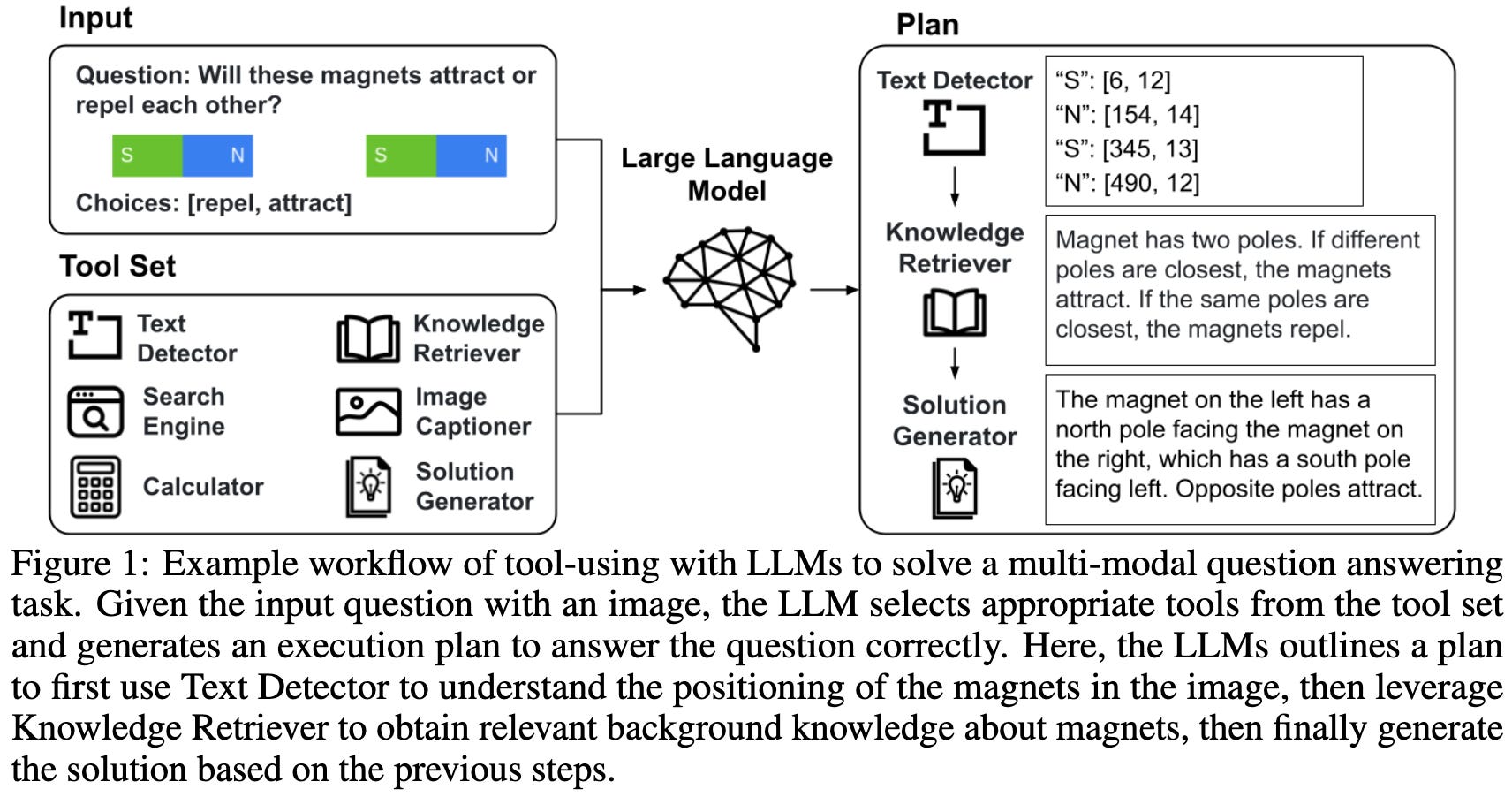
They propose to also feed in docs for the APIs.

As you would hope, feeding in docs helps a lot.
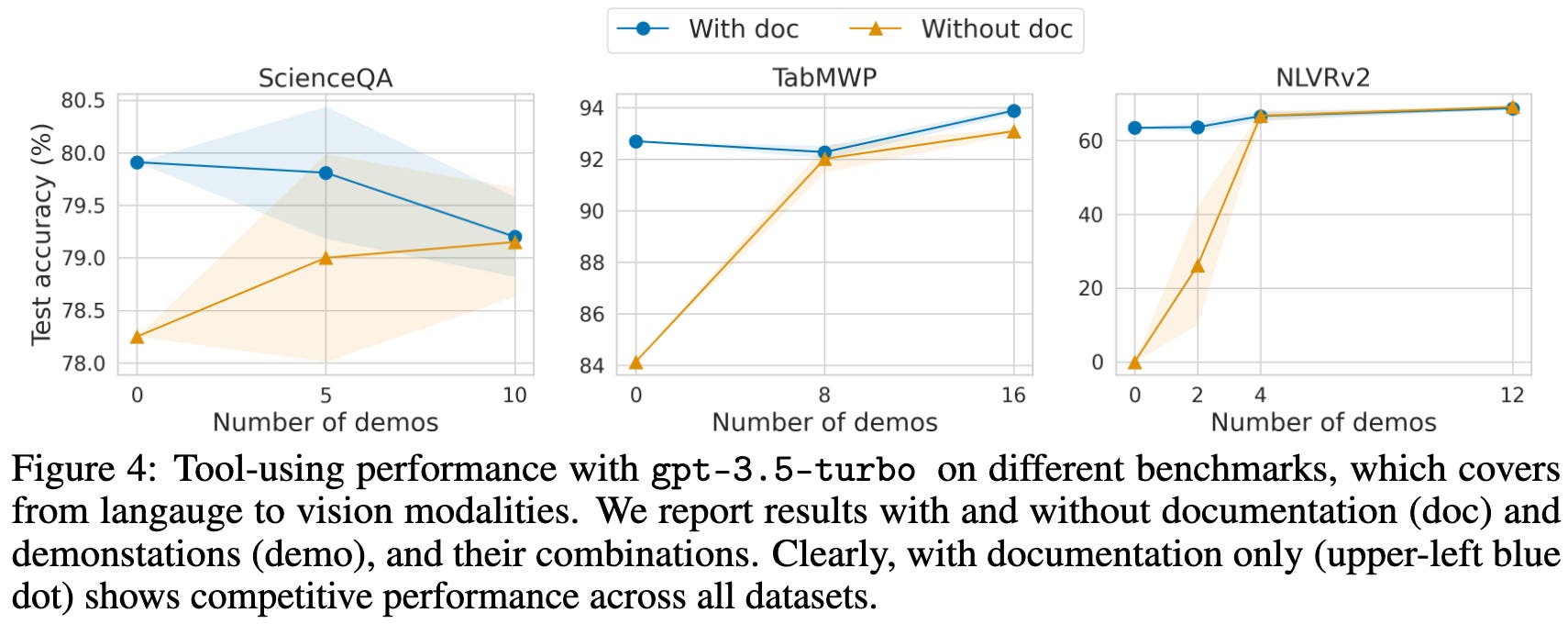
In some cases just having docs is so effective that adding in demos only hurts the output quality.

Sometimes just showing the model the API docs is so effective that you can compose different tools to do something cool with no demonstrations at all.

Although you do have to make sure your docs are of an appropriate length or the model has a harder time using them.

Always nice when something that seems like it should help actually does, since this is often not the case in deep learning.
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
They scale up tool use to 16,000 APIs by adding an API retrieval step, among other changes. They also introduce ToolBench, a dataset of tool use traces generated using ChatGPT and a custom depth-first-search procedure.


RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
They represent robot actions as tokens and train big multimodal models to output these tokens. Because of the training on text + images, the model has some world knowledge, scene understanding, etc, that can help it control a robot better.

For example, they can do cool stuff like have a robot follow text instructions.


I’m not a robotics person at all, but the part that stands out to me here is that bigger seems to be working better.
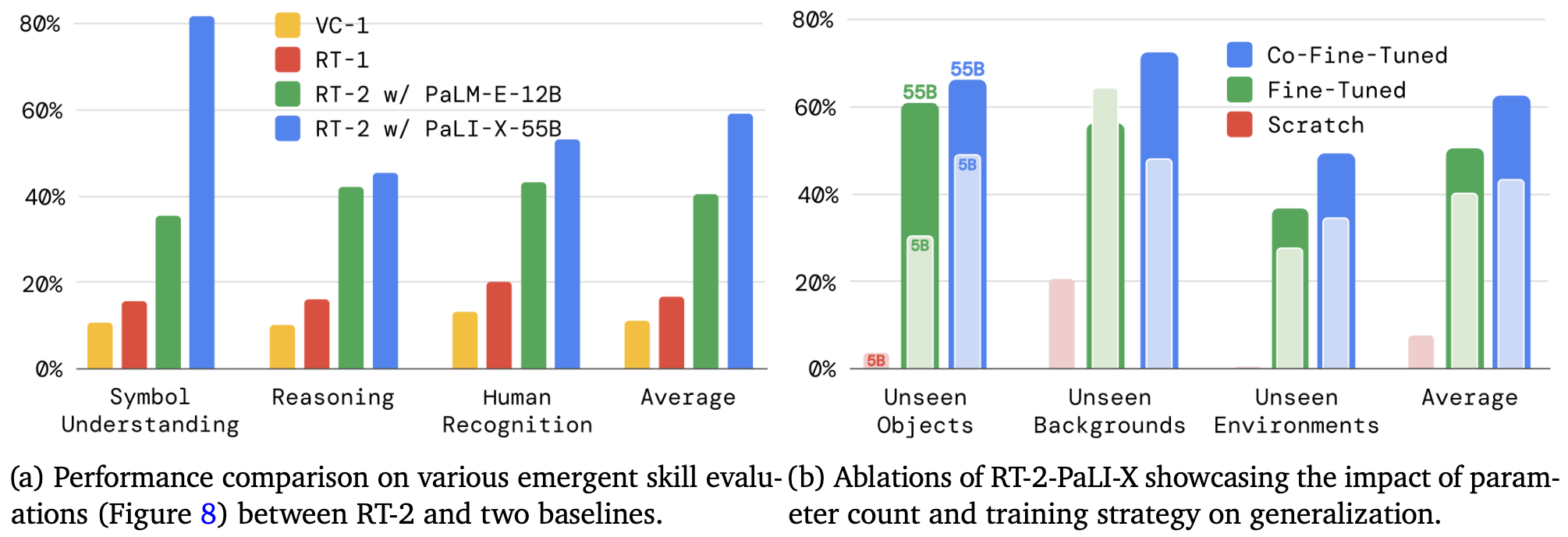
Scaling up has probably been the single most effective strategy for improving deep neural nets, so if we can use this hammer to make robots more capable and reliable, that might be a big deal. As the authors put it:
This simple and general approach shows a promise of robotics directly benefiting from better vision-language models, which puts the field of robot learning in a strategic position to further improve with advancements in other fields.
More speculatively, maybe robotics will be the successor to vision and NLP as the next big deep learning wave?
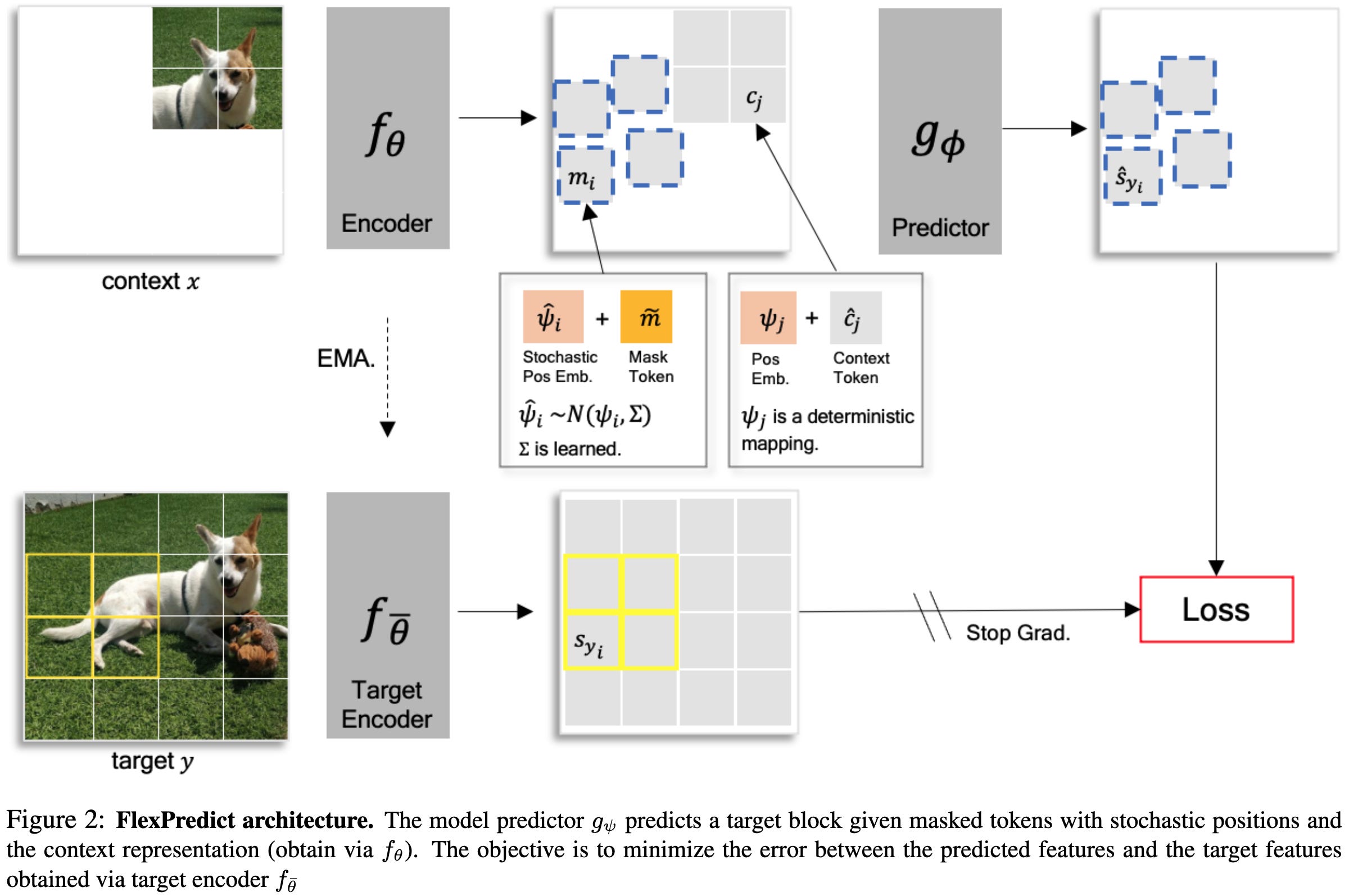
Predicting masked tokens in stochastic locations improves masked image modeling
Normally with masked image modeling, we split the image into disjoint patches, mask out some of the patches, and have the model try to fill in the masked patches. They find that you do a bit better if the masked patches are placed stochastically, instead of always being disjoint + aligned to a grid.

Matrix Completion in Almost-Verification Time
I don’t really follow this literature at all, but this feels like a super cool theory result. Basically, you can sample a small number of random elements from a low-rank matrix and approximately recover almost all the entries of the matrix.
And you can do it in almost the number of samples you fundamentally need based on information theory (just off by an o(1) in the exponent). The runtime is also within an o(1) exponent of the best known algorithms for checking a given solution.

Intelligent Assistant Language Understanding On Device
Apple wrote a paper about Siri. It uses embeddings from a distilled bf16 Tiny-BERT to represent queries. There are a bunch of hard problems and design goals here.
For one, much of the vocabulary is user-, device-, or conversation-specific. E.g., I once heard an Apple researcher talk about how they have a whole model dedicated just to guessing how to pronounce the names of all your contacts (so Siri can understand when you say to message them or whatever).

Another challenge is that verbal and written language are often different.

They also want to do as much processing on-device as possible for privacy, as well as make the system modular and maintainable. Modularity is essential for all the reasons it normally is in software, plus it makes labeling easier and less ambiguous.

Evaluation is hard because a) eval is always hard in NLP, b) you don’t have access to users’ on-device data, c) labeling is hard, and d) there are often multiple right answers. Regarding (d), apparently only 10-50% of model-level errors lead to “user-facing errors.”

The basic approach they take is parsing text into a hierarchical representation based on “domains,” “verbs,” “attributes,” and “values.”

They train their model to output this sort of hierarchical representation, disambiguating tokens as needed.

This hierarchical representation seems to help accuracy a lot.

Mostly I think assistants like Siri, Cortana, Alexa, etc. are interesting case studies for predicting the future of AI. One take on the future is that we’re just going to scale up blobs of parameters and someday one blob will get big enough that it just outperforms everything else at everything. But what we’re actually seeing in large-scale AI systems like these assistants, search engines, and self-driving cars is that they’re:
decomposed into a number of specialized components, and
products of a ton of domain-specific knowledge.
This is probably a good sign, since modular software systems are much easier to reason about, test, modify, etc, than a big pool of “intelligence” would be.
Continual Pre-Training of Large Language Models: How to (re)warm your model?
Let’s say you want to warm start your pretraining run from a previous pretrained model, instead of starting from scratch. What’s the best way to do this?
They summarize their results in a few concise takeaways:




Note that they were kind of computed-limited in their experiments though, focusing on a 410M parameter Pythia model and a subset of SlimPajama.

So…warm starting is definitely better than starting from scratch, but be careful and listen to their guidance when it comes to your learning rate schedule.
Experts Weights Averaging: A New General Training Scheme for Vision Transformers
They use MoE as a form of training-time regularization for ViTs, keeping the test-time architecture MoE-free. During training, they make a bunch of copies of the FFNs and route tokens to experts uniformly at random.

This approach raises accuracy on a variety of tasks compared to vanilla training.

Interestingly, you can also use their approach on a regular MoE model for the first half of training to make the MoE model work better. This basically means they do random routing and tie the weights initially. Apparently starting the experts off in a better (and identical) place matters more than having half as many samples for the experts to learn specialization on. Maybe a bias vs variance tradeoff, since these are small datasets?2

Further evidence that MoE-as-regularization can sometimes work well; still unclear though how this relates to MoE-as-more-parameters.
Pre-gated MoE: An Algorithm-System Co-Design for Fast and Scalable Mixture-of-Expert Inference
Instead of having a given module’s router determine the expert assignments for this module, they have it determine the assignments for the next module.

This lets them prefetch only the needed expert(s) from CPU RAM during inference.
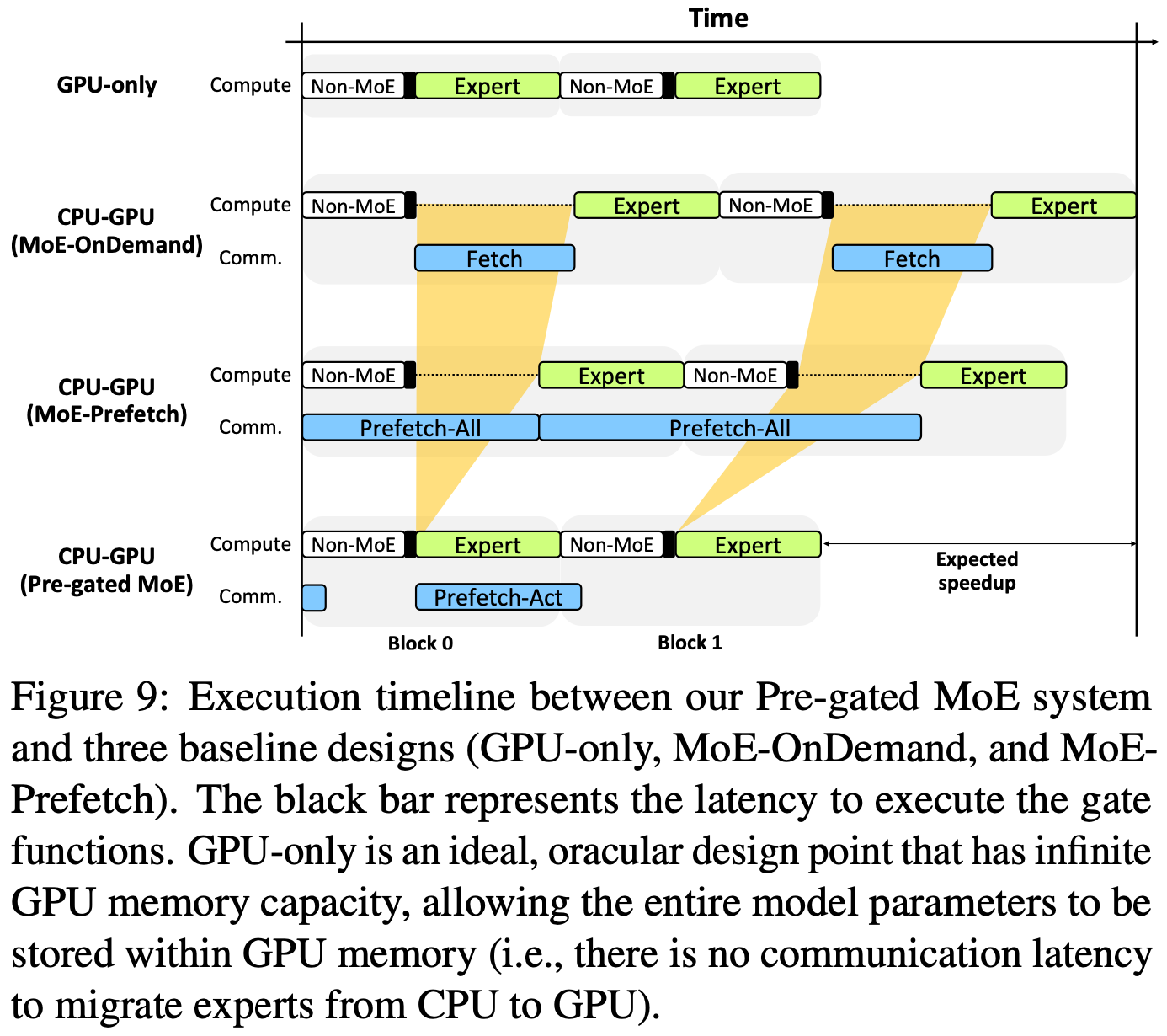
This can improve MoE inference latency a lot compared to loading the necessary experts just-in-time or prefetching all the experts from the CPU.

Their pre-gated MoE isn’t quite as fast as just caching all the experts on the GPU, but it saves tons of memory.

They also found that routing their way improves accuracy on a few tasks, although I’m not sure why this would be the case.

Might be an actionable win for various MoE sharding/offloading setups.
EVE: Efficient Vision-Language Pre-training with Masked Prediction and Modality-Aware MoE
They propose to do multimodal pretraining by masking out both image patches and text tokens and jointly trying to predict both. They call this “masked signal modeling.”

They also use sparse mixture of experts modules with learned, modality-specific biases added to each token. This changes the routing behavior based on modality.

Their objective + MoE layers together let them beat a variety of existing baselines in terms of accuracy vs training time.


I like the simplicity of learning the conditional distribution of every output with respect to every other output. I feel like this is what I would try coding first if I were going to sit down and pretrain a multimodal model.
Curriculum Learning with Adam: The Devil Is in the Wrong Details
Curriculum learning methods might just be effective because of an interaction with poorly-tuned Adam hparams. In particular, many curriculum learning methods end up just progressively increasing the difficulty of samples throughout training, which causes increasing gradient magnitudes. With β2 > β1 in Adam (the common case), this makes the optimizer take larger steps.

If you tune the Adam hparams better, the baseline with no curriculum starts beating the curriculum.

Divergence of the ADAM algorithm with fixed-stepsize: a (very) simple example
You can construct a simple 1D function that will make Adam oscillate forever instead of converging.


Efficient Benchmarking (of Language Models)
They do a big, systematic analysis of HELM and how the results vary when you use fewer samples or otherwise save compute. Based on these results, they propose Flash-HELM, an eval suite that runs 100x faster but ranks models basically the same way.
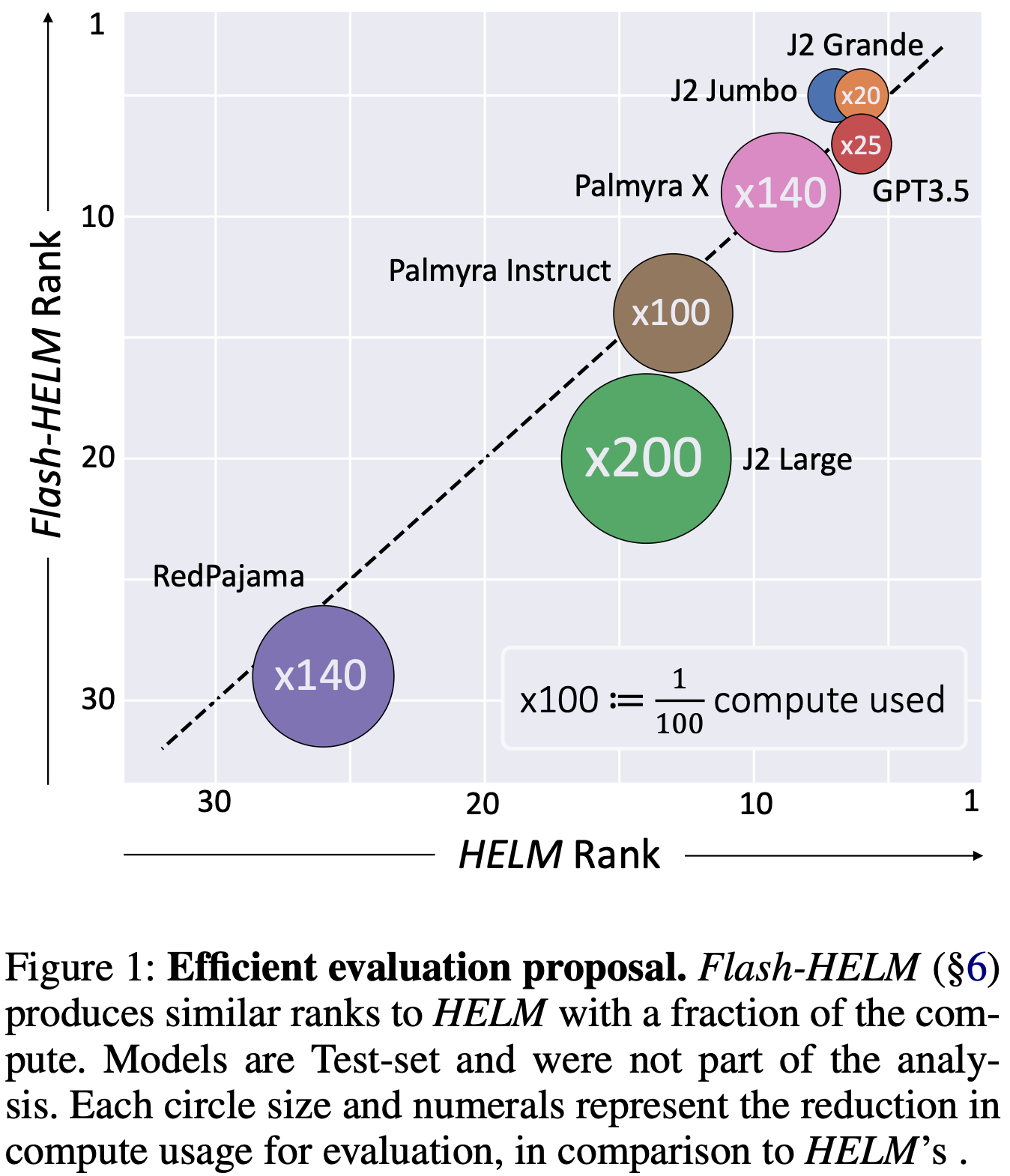
This works because you don’t need that many samples to properly order models in most cases.

They also propose a few guidelines for designing efficient and reliable benchmarks more generally.

Graph of Thoughts: Solving Elaborate Problems with Large Language Models
Why stop at a tree of thoughts when you can generalize to a DAG?

This generality lets you combine or split intermediate outputs; for example, you can combine multiple passages into one passage or split one array into several subarrays.

This seems to help with synthetic tasks like sorting, keyword spotting, and set intersection. It might also help for document merging.

Makes me wonder where the limit will be as far as fancy techniques to squeeze test-time accuracy out of a fixed language model.
Also check out Cameron Wolfe’s post for more detailed coverage of this paper + some similar work:

Activation Addition: Steering Language Models Without Optimization
They propose to perturb LLM activations in a manner similar to how people perturb GAN latent spaces.

Concretely, you feed in a positive prompt, a negative prompt, and an actual prompt. You diff the activations from the first two prompts and add them to the activations of the final prompt to “steer” them as you run the forward pass. E.g., you might perturb each layer’s activations in the direction of “love” minus “hate” before moving on to the next layer.
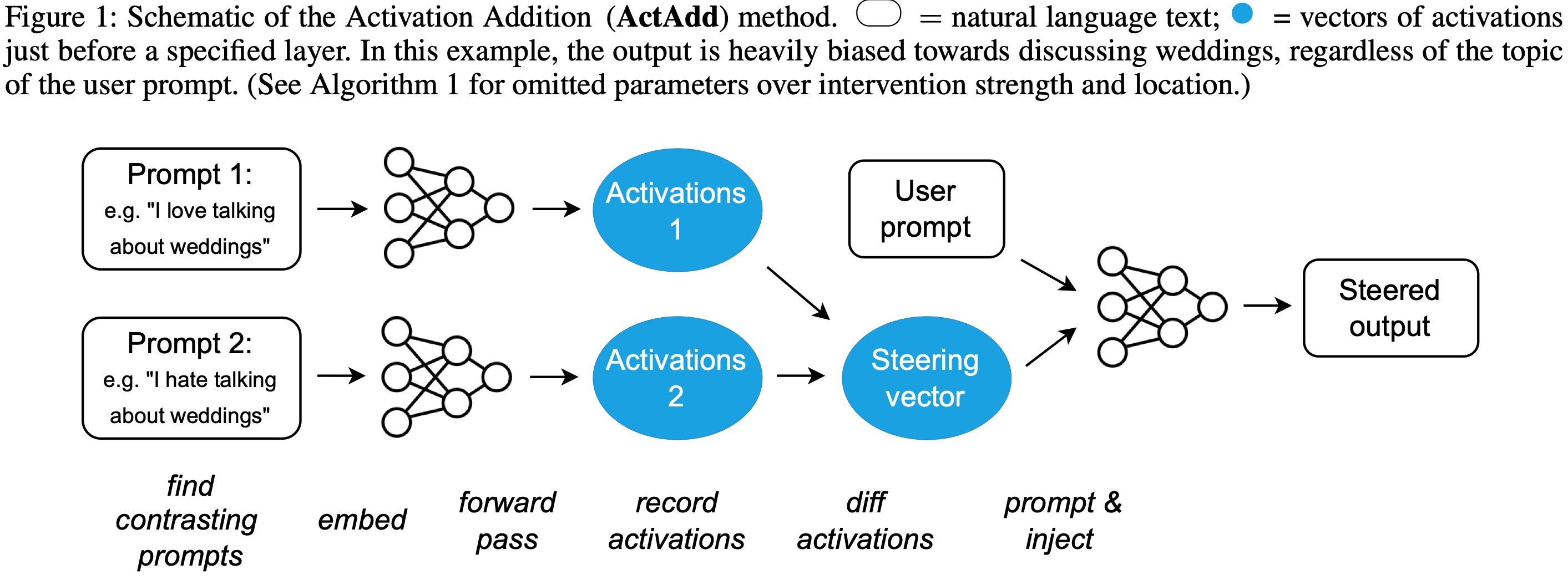

It’s hard to evaluate whether something like this “works,” but it certainly seems worth a try as a prompting technique.
Instruction Tuning for Large Language Models: A Survey
Big old survey of instruction tuning techniques, datasets, and public models.

Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions
For anyone who didn’t know, LLMs can be biased towards certain answer positions when given multiple-choice questions. This can ruin your eval if you aren’t careful.
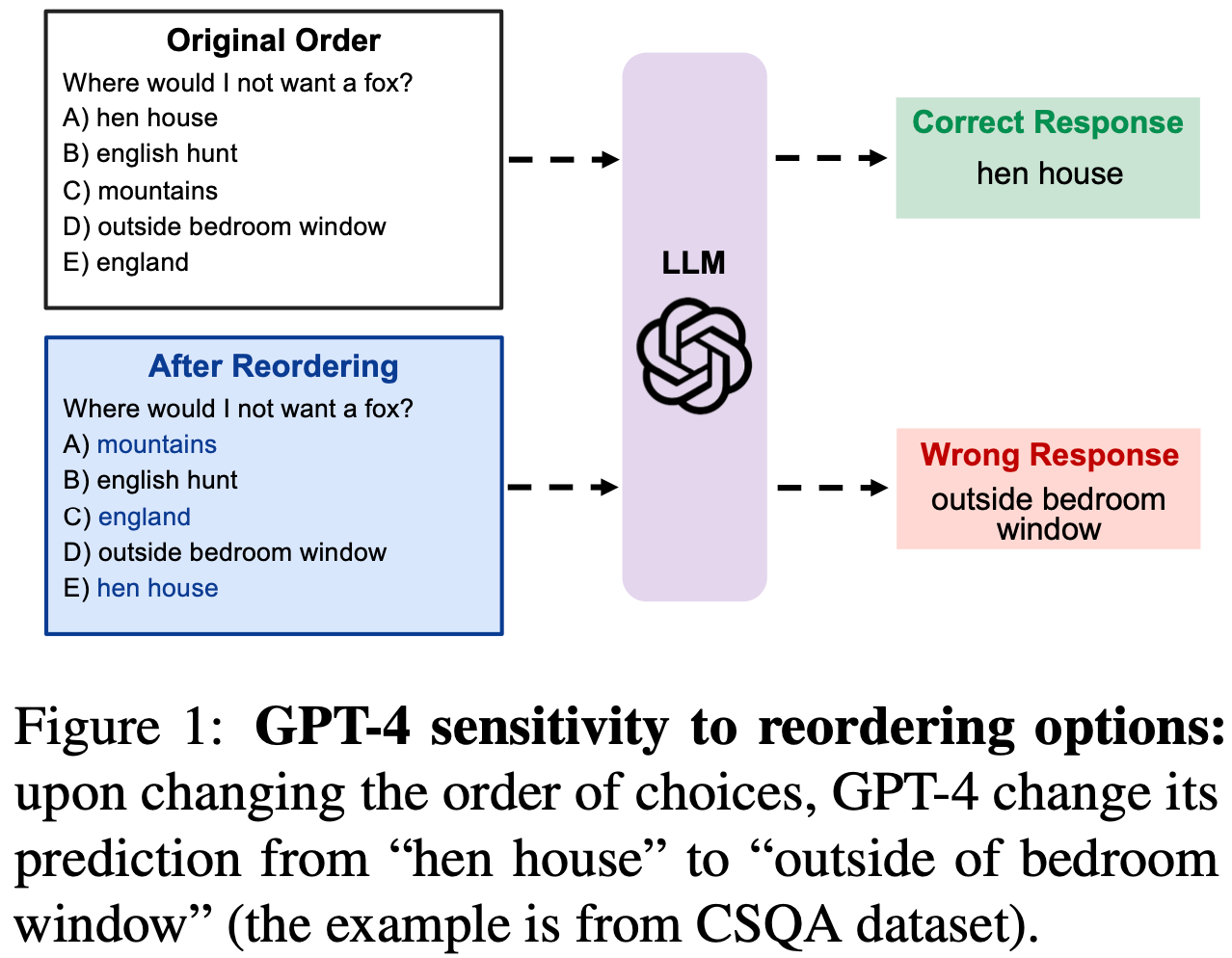

Averaging predictions over 10 random orderings of the options is a reliable way to counteract this. Having the model generate a rationale before giving an answer can also counteract this, but is more hit-or-miss.
D4: Improving LLM Pretraining via Document De-Duplication and Diversification
They propose to filter text datasets by:
Running k-means on text embeddings and removing points within each cluster there are within a small epsilon of each other. This hopefully removes approximate duplicates.
Running k-means on what’s left and removing some fraction of the points within each cluster that are the most similar to the cluster centroid. This hopefully removes uninformative points / leaves a diverse subset.

This seems to improve time-to-quality compared to not filtering.

It also seems to do better than either step alone (semdedup and ssl_prototypes, respectively).

They can even do better with multi-epoch training than single-epoch training when the multi-epoch uses samples from their filtering pipeline.


Their method often hurts validation metrics for datasets that are snapshots of (large portions of) the internet. This seems to be because the associated validation sets are unusually close to the training sets in embedding space; this means that the proposed sample pruning heuristics are more likely to filter out points that would be helpful for these validation sets.

LLM data cleaning is still poorly understood as far as I can tell, but it’s great to see a simple method that works well at billion-parameter scale according to meaningful cost metrics.
As far as I can tell. There doesn’t seem to be an official list or anything.
I’ve personally never managed to get a positive result using MoE on CIFAR-100
The results for pre-gated MoE probably only *look* good, because of a slow implementation of the model to begin with. Their baseline speed for switch-base on a PCIe A100-80G is 120~150 generated tokens/s on batch size 1, which is a little bit pathetic for ~200M activated params these days -- it's comparable to the tg128 speed of 4-bit quantized llama-7b.
Because the PCIe latency bottleneck still remains regardless of how much more efficiently the flops are used, the proportion of latency consumed by loading experts should become far worse.
Maybe it will work better with Grace Hopper's bridged memory.
Do you want to collab? Seems like we have synergistic audiences