
2024-4-7 arXiv roundup: DBRX, Backlog highlights part 1

It’s good to be back.
Now that DBRX is out, I’m no longer in deadline mode and can actually write again.1 Speaking of which:
Introducing DBRX: A New State-of-the-Art Open LLM
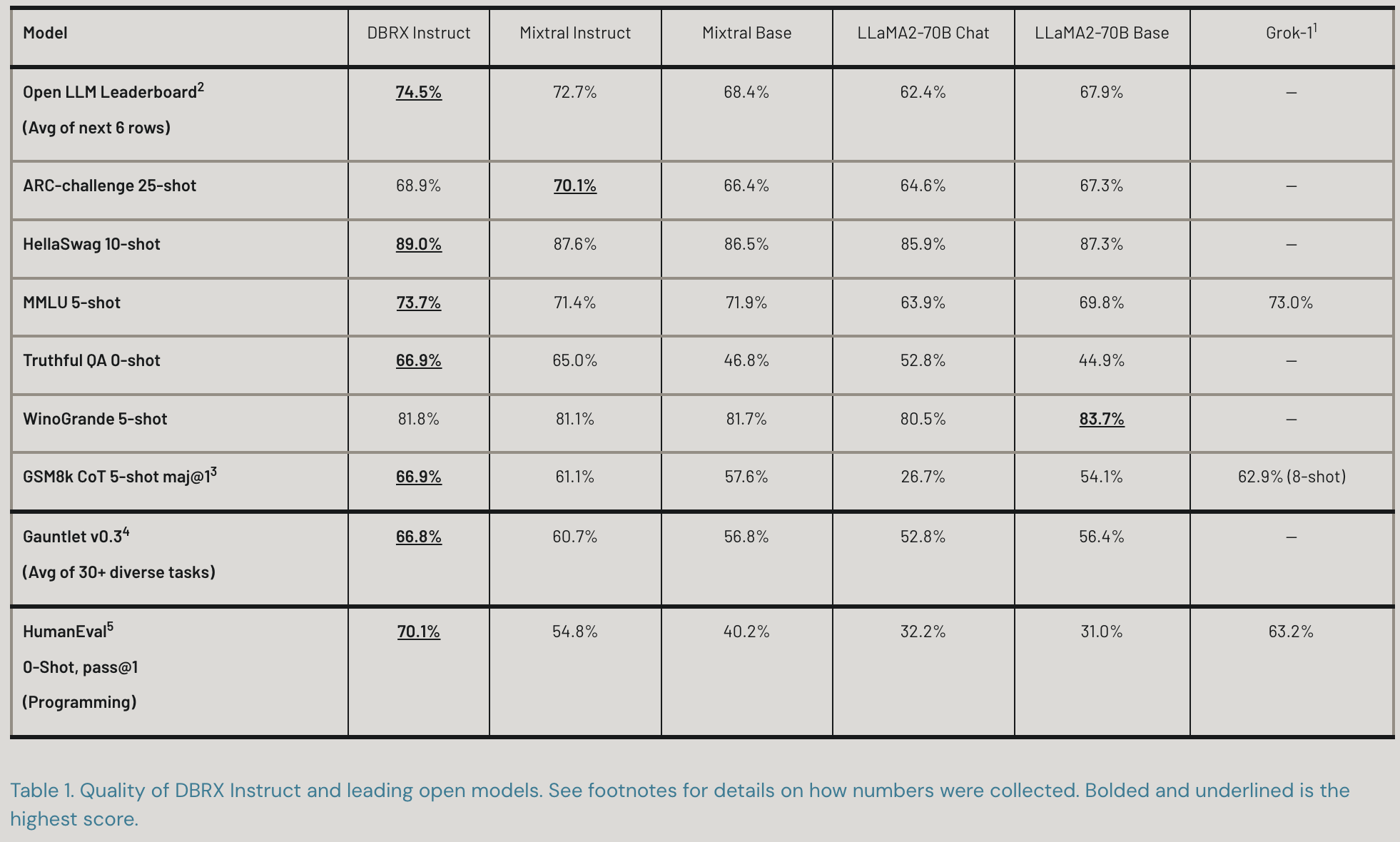
We trained a 132B param MoE model on 12T tokens that beats all other open models and the original version of GPT-3.5.
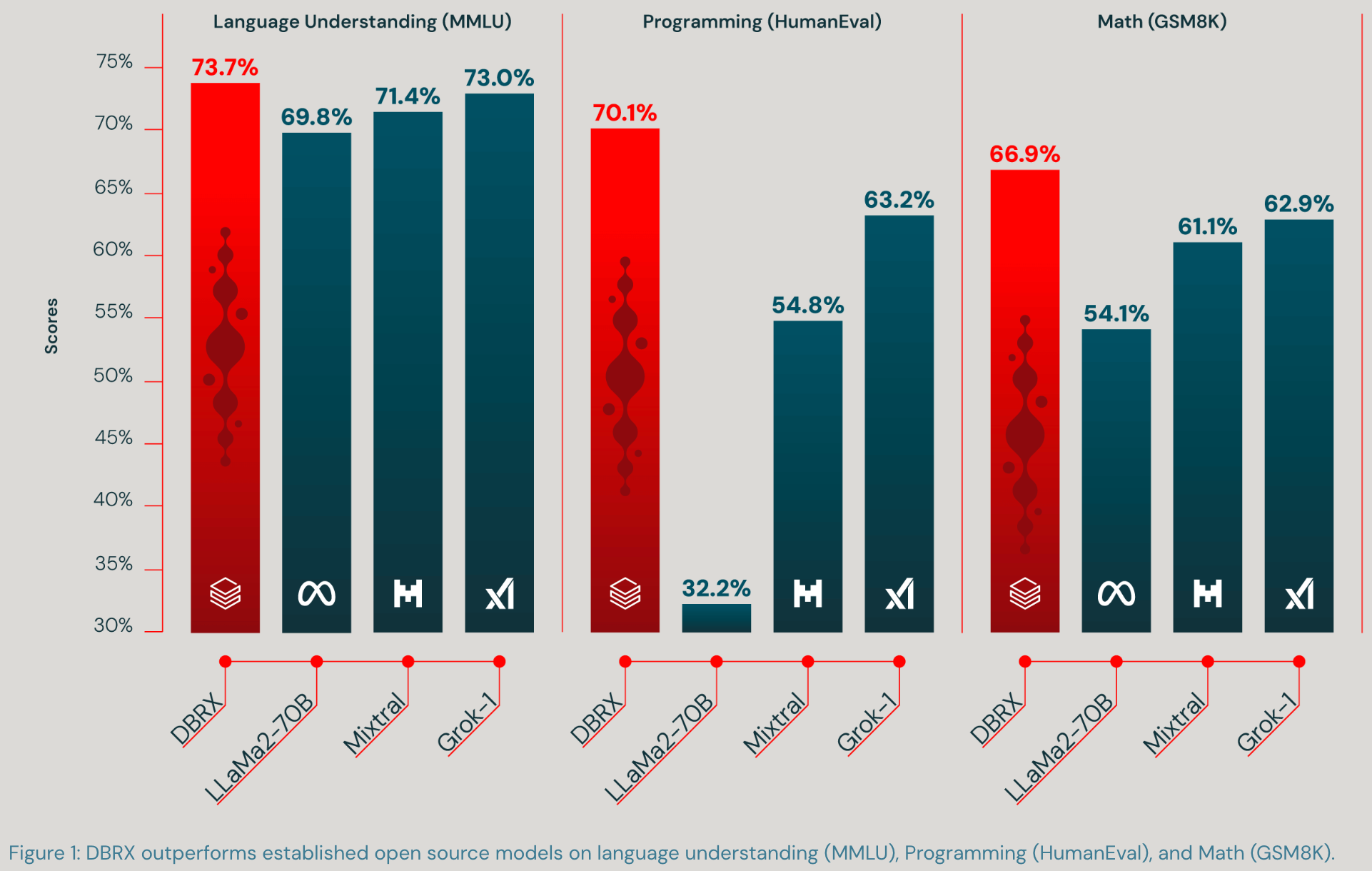
We evaluated the crap out of this thing and I could regurgitate the claims point by point here, but what I think is most valuable to share is some perspective from building it.
People sometimes have this impression that big LLMs are like this space race where we stand around at whiteboards having breakthroughs and the company with the most talent or insights gets the best model.
The reality is much less sexy than that. We’re basically all getting the same power law scaling behavior, and it’s just a matter of:
Parameter count
Training data quantity / epoch count
Training data quality
Whether it’s an MoE model or not
Hyperparameter tuning
The real innovation is in dataset construction and the systems you build to scale efficiently.
It also takes immense skill to debug the training, with all sorts of subtleties arising from all over the stack. E.g., a lot of weird errors turn out to be symptoms of expert load imbalance and the resulting variations in memory consumption across devices and time steps. Another fun lesson was that, if your job restarts at exactly the same rate across too many nodes, you can DDOS your object store—and not only that, but do so in such a way that the vendor’s client library silently eats the error. I could list war stories like this for an hour (and I have).
Another non-obvious point about building huge LLMs is that there are a few open design/hparam choices we all pay attention to when another LLM shop releases details about their model. This is because we all assume they ablated the choice, so more labs making a given decision is evidence that it’s a good idea. E.g., seeing that MegaScale used parallel attention increased our suspicion that we could get away with it too (although so far we’ve always found it’s too large a quality hit).
In that spirit, here’s DBRX (pronounced2 “D-B-R-X” or “D-B-Rex”) in the low-dimensional space of LLM design choices. We ablated almost all of these at smaller scale.
LayerNorm, not RMSNorm
QK clipping to fix loss spikes, not QK LayerNorm (AFAIK no one else does this because Vitaliy invented it)
LION optimizer, not Adam
A lot of data curation. I can’t comment on what we trained on (or even what we didn’t train on!) because lawsuits have started flying. But suffice it to say, we could have made certain numbers go up a lot more if we were less principled. We also didn’t train on any test sets (at least intentionally), although we did do targeted dataset construction with certain benchmarks in mind.
RoPE rather than Alibi. Alibi was never worse quality and we used it for MPT, but RoPE has better software support across hardware.
4-of-16 mixture of experts instead of 2-of-8 using MegaBlocks. This granularity is consistent with the view of MoE as a sparse matrix product. The funny/frustrating story here is that we’d been adding to + using MegaBlocks for months when Mixtral came out and got all the brand recognition from it.
Serial Attention + FFNs (not parallel)
No attempt to hide the system prompt. Here it is, with comments.
In terms of results, we have a ton of tables in the technical blog post, but what really stood out to me was how flaky different evals are and how hard it is to get your eval harness right. Like, for a while, we logically could not get 20% of the HumanEval questions right because of a bug in our eval code.
Besides raw quality, DBRX is also fast. Since it’s an MoE with only 36B active params for a given token, the number of FLOPs you have to do for inference is much lower than for a 70B model.

We also optimized the crap out of our training stack. We only talked about dense models in this post to not spoil the MoE part, but most of that content applies here. I can’t tell you absolute MFU, but we managed to get about a 1.4x speedup from in-house optimizations after squeezing everything we could out of off-the-shelf libraries.

Besides the technical lessons learned, I think this model has interesting implications for the ecosystem.
For one, it’s going to be increasingly hard for open models to one-up each other. Last year, you could get noticed by releasing a 7B model. At that scale, a startup can justify it as a pure marketing expense. But if you need to drop $10M+ on the training…that’s hard to fit into a marketing budget. Only the companies with serious ROI can justify that. This excludes almost everyone but:
Popular API providers who can amortize the pretraining cost across many paid queries
Companies helping enterprises build custom models who need to pipeclean their training stacks (us and Microsoft, plus a few other startups trying)
Companies selling the promise of “AGI” who need SotA-ish results to raise their next round.
Companies who profit from LLM progress in general and needed to train a big model anyway (Meta, Google, various Chinese firms)
It’s also an interesting datapoint around AI progress. DBRX would have been the world’s best LLM 15 months ago—and it could be much better if we had just chosen to throw more money at it. Since OpenAI had GPT-3 before MosaicML even existed as a company, this indicates that the gap between the leaders and others is narrowing (as measured in time, not necessarily model capabilities). My read is that everyone is hitting the same power law scaling, and there was just a big ramp-up time for people to build good training and serving infra initially. That’s not to say that no meaningful innovations will happen—just that they’re extremely rare (e.g., MoE) or incremental (e.g., the never-ending grind of data quality).
But anyway, hope you all enjoy it! Here’s the GitHub repo, 🤗 model, and interactive demo (it says CPU, but it’s running on a GPU in our inference stack).
Mechanistic Design and Scaling of Hybrid Architectures
There have been a bunch of proposed non-transformer architectures in the past few months, like Hyena, Mamba, RWKV, Griffen, and more. Instead of proposing yet another SSM/RNN-like model, they try to devise a principled way of making architecture choices.

The first part of their work is devising a set of simple synthetic tasks that test how well models can learn different primitives. Think selective copying, fuzzy matching, or memorizing key → value mappings.

They evaluate various small models with different architectures to check how these architectural choices affect accuracy across these tasks.

A few patterns stick out in these results. First, you’re better off using a mix of different types of token mixing—e.g., not just attention, but attention along with something more SSM-like at another layer.

You also want larger heads rather than more heads. I’m reading this as more mixing of feature dimensions, although the details vary by architecture.

As you would hope, mixture of experts is beneficial.

The real tests though is whether accuracy on these simple benchmarks is predictive of model quality when the architecture and training are scaled up. The correlations are imperfect for each individual task, but when you average across all of them, the toy tasks become a good predictor.

They also assess whether the finding that you should use other token mixing schemes to supplement attention holds at scale. Looks like it does, with the optimal fraction of attention being around 25% of the relevant layers.

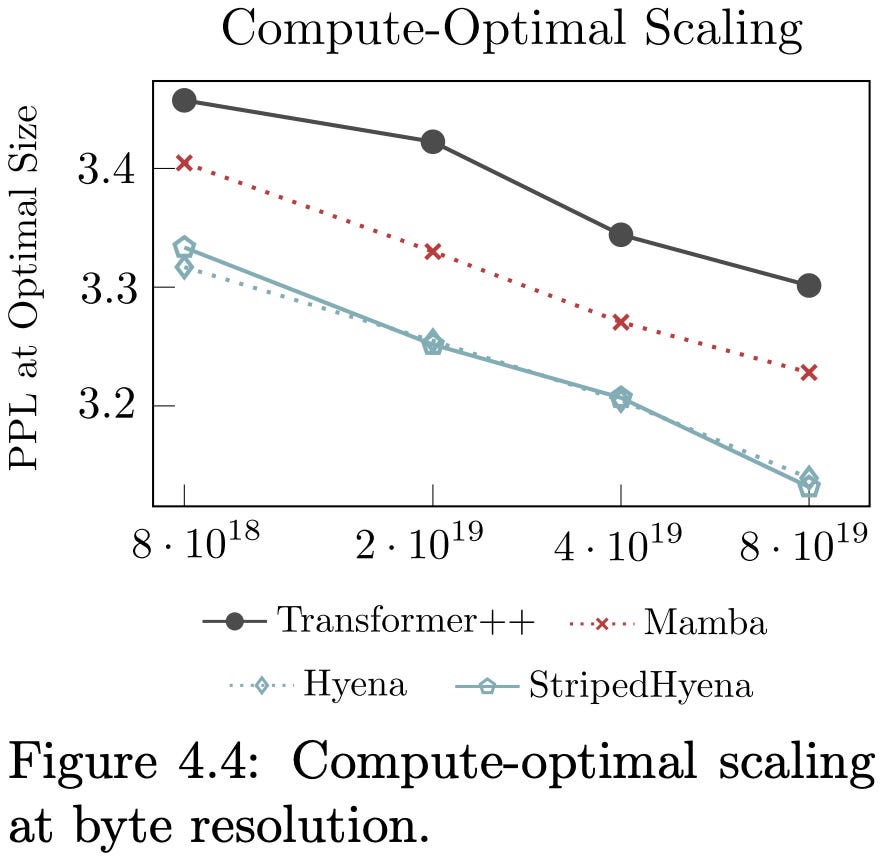
My favorite experiment is this investigation of how perplexity varies with state size. By “state size”, we mean the KV history for transformers or the latent state variables for SSM/RNN variants. You get clean fairly clean power law scaling (exponent -.28) within a given class of architectures, but there’s no overall Pareto frontier that everything lies on. It looks like multi-headed SSM variants can get the same perplexity as other variants that need 10-100x larger states. However, the overall appeal of models depends on whether you’re looking at compute (left) or state size (right).

Also, the ordering between different models’ speed vs quality tradeoffs can vary across tasks. E.g., SSMs look a lot better than transformers when you operate on individual bytes without using a tokenizer.
I’m a fan of papers that try to get to the truth instead of sell you on yet another method, and this is no exception. I’m also excited that someone swept state size vs perplexity and just plain characterized the scaling curves for all these different approaches.
I’m also a fan of trying to get tighter feedback loops around design choices, since that’s a super important problem in practice.
And lastly, it’s nice to see corroboration that simple synthetic tasks can be a decent proxy for real data in certain cases.
Speculative Streaming: Fast LLM Inference without Auxiliary Models
In speculative decoding, we use a lightweight model to estimate what the next tokens are and our real model to “check” these tokens. With some clever rejection sampling, you can reduce the number of forward passes through the main model without changing the output distribution at all.

But…why have a separate model to generate the next token proposals? Why not just stick some extra classifier heads on top of our main model, one per future token position you want to generate?
Well, you can. That’s more or less Medusa.
The problem with this is that the classifier heads have a lot of parameters and, if you’re Apple, you’re trying to do this on an iPhone. So you’d rather find a way to reuse the same classifier head you already have.
To do this, you have to instead generate a bunch of extra token embeddings to classify, one per speculated token. They derive these embeddings from the observed tokens’ embeddings partway through the network.

They feed these derived embeddings in starting at one of the later layers and have them attend to the observed tokens, as well as earlier speculated tokens. To increase their probability of having some speculated tokens accepted, they speculate a tree of possible completions instead of just one long completion. Hopefully at least some prefix of the tree will be accepted. This makes the attention masks complicated, but these masks are at least fixed across all iterations.

I’m not sure why (perhaps because of the modified training objective?), but this approach doesn’t preserve the semantics of typical autoregressive decoding. Although it seems to work about as well across various tasks.

Getting people to change their model semantics is always an uphill battle, but it does seem unnecessary to have a separate model to generate the proposal distribution. And if you’re going to get a proposal distribution out of your target model without (significantly) increasing the parameter count, this seems like a sensible way to do it.
The Unreasonable Ineffectiveness of the Deeper Layers
Consistent with previous work, they find that the representations in later layers of the network tend to be more and more similar to each other. Does this mean we can just remove a lot of these layers?

Sort of. For downstream tasks, you can often remove a big suffix of the network (excluding the final classifier head) without hurting model quality for downstream tasks. This is especially true if you run some QLoRA to “heal” the network. But for validation loss on C4, it’s tradeoffs all the way down (see how linear the lower right is).

I think of successive residual blocks as performing steps of gradient descent in activation space.3 So I’m reading this as suggesting that, for many tasks, the samples are so separable that the fine activation adjustments from the later layers aren’t needed.
Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
Similar to Branch-Train-Merge and it’s follow-up paper, but instead of ensembling the different “branch” LLMs at test time or weighted averaging them into one dense LLM, they use the different models to initialize the experts for a single model.

They use a slightly atypical load balancing loss, which replaces each expert’s token count with its total softmax weight without the top-k operation. I’m not sure why that’s desirable—maybe it increases the gradient flow to routing weights for experts that weren’t selected?


A component of this loss that seems counter-intuitive at first glance is that they scale the sum over the N experts by N, rather than 1/N. But the reason you do this is that:
the average softmax output scales as 1/N and
b) we’re squaring these outputs for each expert. This means the per-expert loss scales as 1/N^2.
So summing over N experts still yields a total loss that scales as N * 1/N^2 = 1/N. Therefore multiplying by N gets us consistent loss magnitude across expert counts.
In terms of results, what they did was start with a LLaMA-2 7B and finetune three copies of it: one on math, one on code, and one on wikipedia. They trained each one on about 200B tokens, and then used these three FFNs, along with the original LLaMA FFNs, to construct 4 experts in each transformer block. They also initialized the attention weights to the average of the weights across all the finetunes.

So how well does it work? On average, it’s way better than just using the initial LLaMA model, as well as each of the individual finetunes. It’s also a bit better than sparse upcycling.
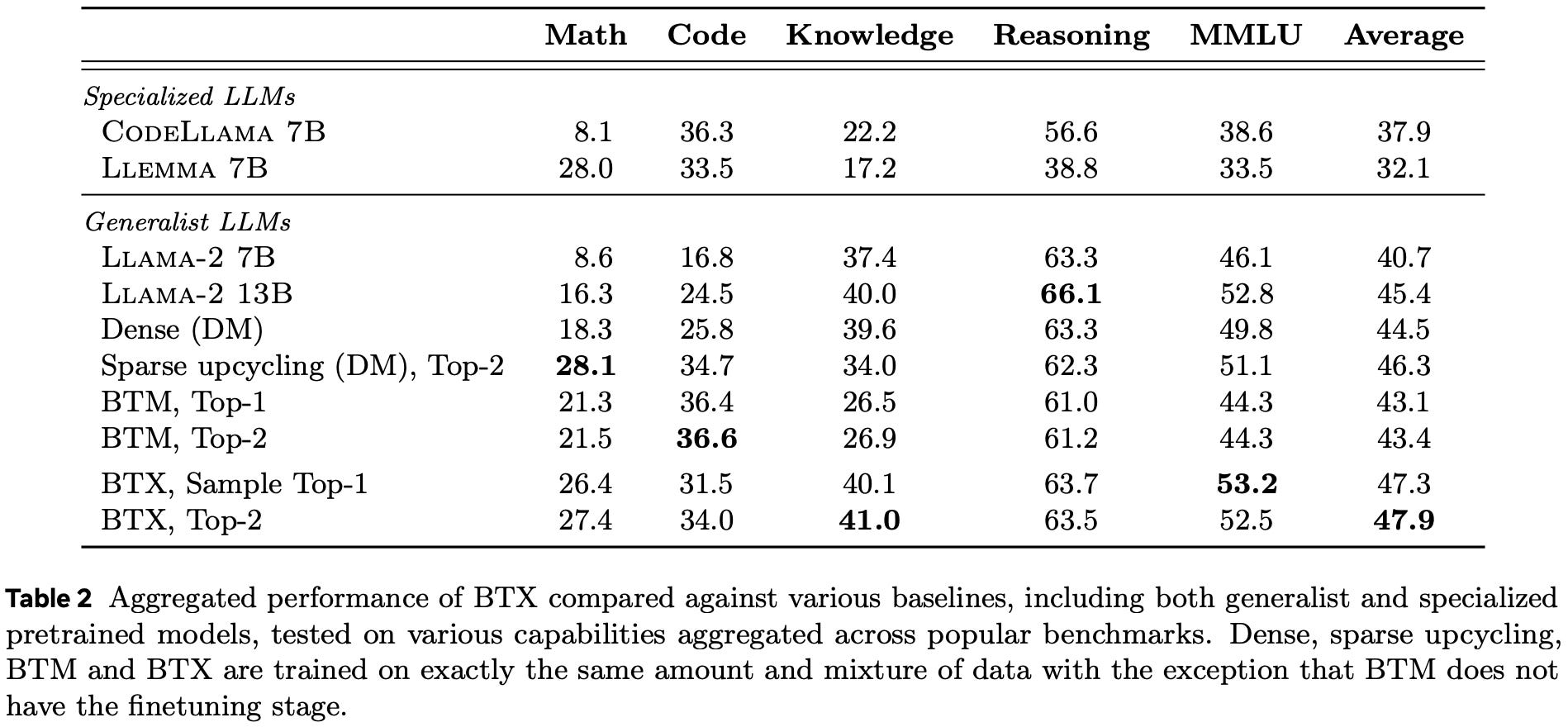
However, the sparse upcycling baseline apparently used far fewer tokens. They gave it more compute time, but it looks like their MoE utilization was so low that a lot of their gains came from just keeping the model dense for a higher fraction of training. For maybe the first time in my life, I wish someone had held FLOPs constant instead of compute time.

Still, their method and sparse upcycling seem to yield a much better training time vs quality tradeoff than any alternative.

They also have a bunch of good ablations. It seems like their sampling based routing (annealed to determinism) works better than more conventional routing (as proposed in the Switch Transformer paper).

The load balancing loss seems to make weirdly little difference overall, but a huge difference for GSM8K (math) and HumanEval (coding).

It’s not clear why these two datasets would be so affected, but they do visualize what’s going on really nicely.

FP6-LLM: Efficiently Serving Large Language Models Through FP6-Centric Algorithm-System Co-Design
You may have heard that NVIDIA’s next generation of GPUs will support fp6 (i.e., 6-bit floating point numbers). And this is the first paper I’ve seen getting fp6 to work in practice.
Concretely, they wrote a fused CUDA kernel that dequantizes fp6 values to fp16 before doing a regular fp16 matmul with fp32 accumulators. This is similar to existing 4-bit and 8-bit kernels for low-bit inference, but with a tricky new format.

There are a bunch of reasons this fp6 kernel is hard. First, 6-bit values aren’t byte aligned. CUDA threads can’t just load a certain 6 bits from memory, and if the values for different threads span the same byte, you can end up with redundant loads. The solution to this is to pack together runs of many 6 bit values so that you can always address byte boundaries.
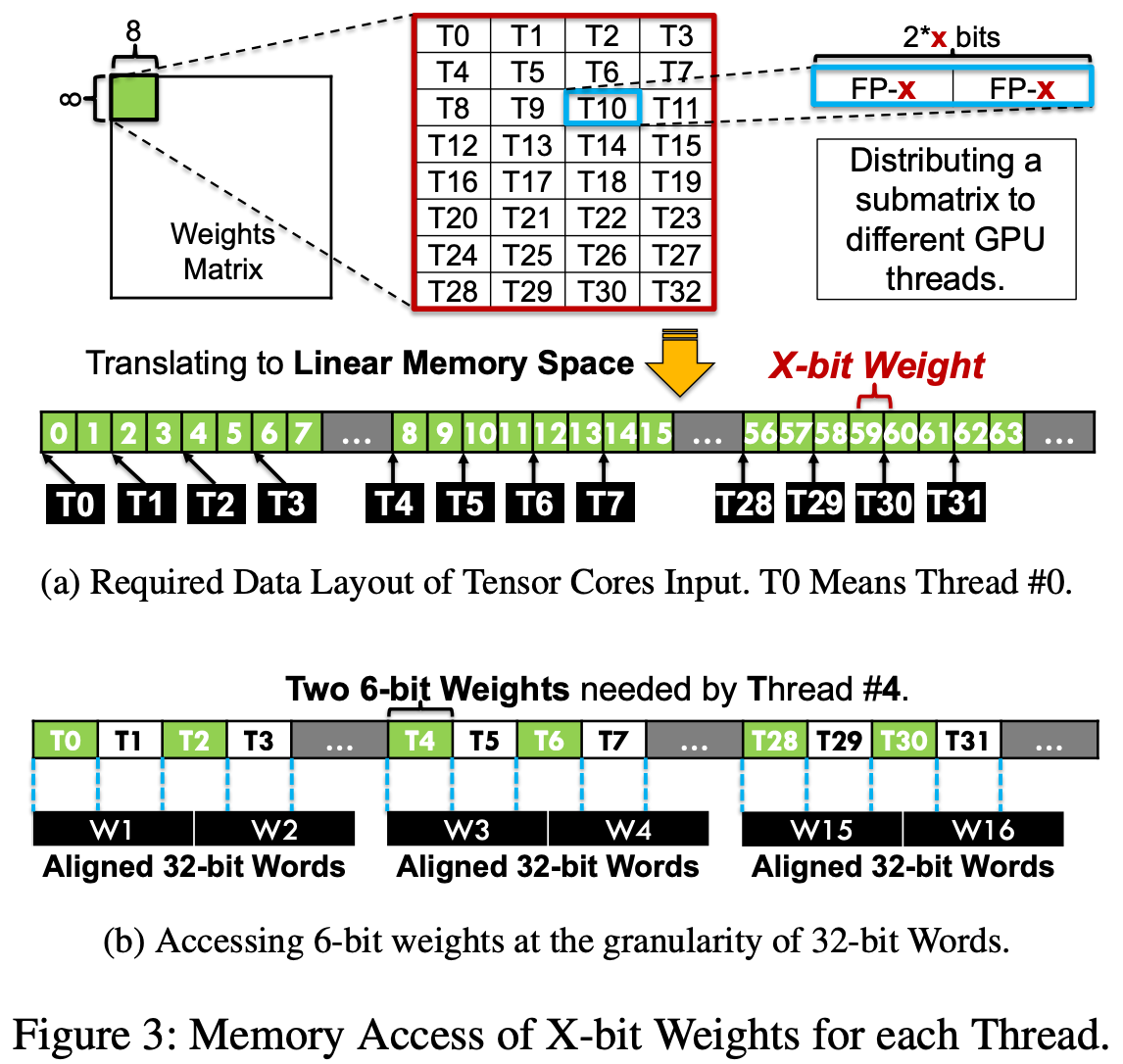
But even this is hard because you want to do wide, power-of-2 reads to get the best memory bandwidth utilization. If you were to load, say, 3 bytes = 4 fp6 values per thread, you’d be doing a 32*3 = 96B read (since CUDA threads operate in groups of 32). But you’d really like to do at least a 128B read. So the lowest multiple of 6 elements is 3x 128B reads = 384B = 512 fp6 values minimum to get nice, wide reads.
But what you need to load in your matmul is a tile, of size 64x64 in their case. So you’re only going to get runs of 64 contiguous values, not 512. So…what do you do?
In short, we’ll shuffle the order of the weights to enable long, contiguous reads while still respecting the ordering required by tensor cores. Essentially, we’re just pre-packing the weight tensor while also taking into account bank conflicts.
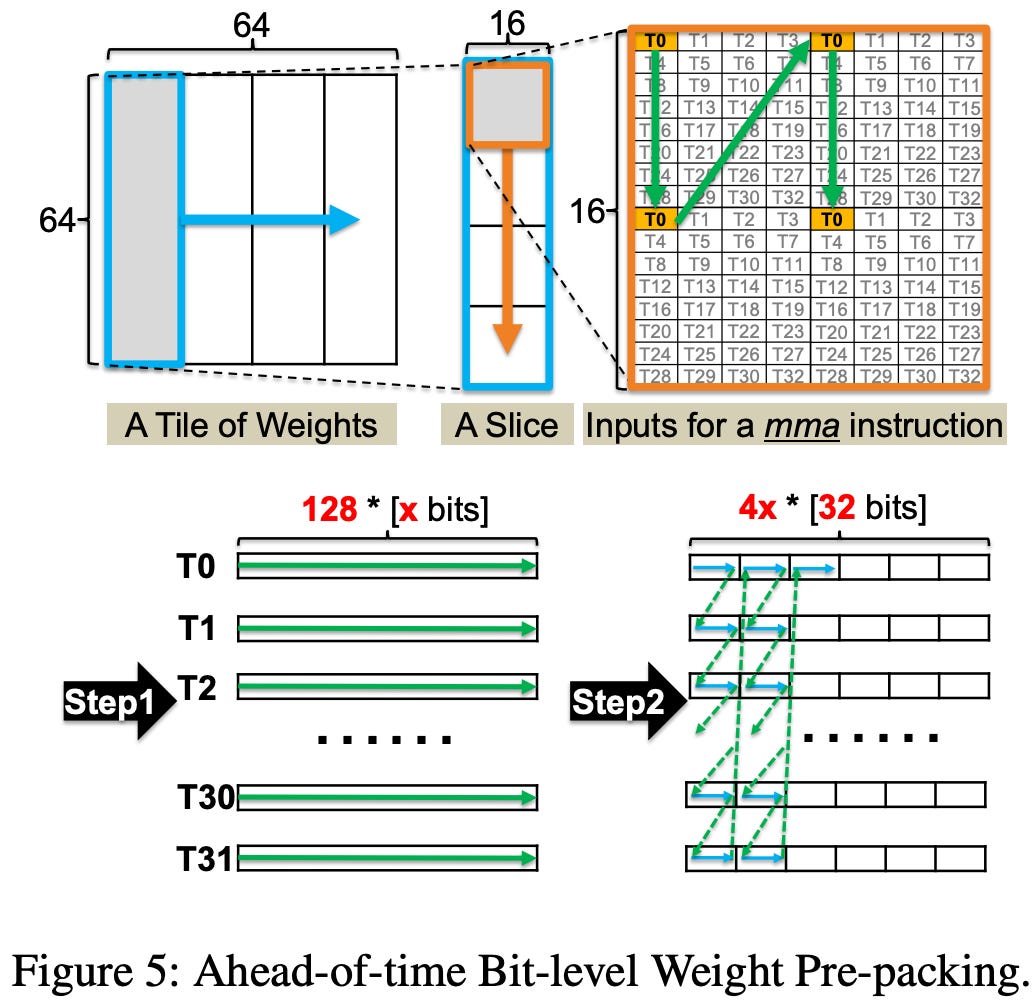
Having the layout already permuted for tensor core loads enables an additional optimization, where we keep the data as fp6 in shared memory and only decompress it a slice at a time in registers as needed. This reduces our shared memory consumption and can improve occupancy.


Their dequantization also does some nice bit twiddling to convert fp6 values to fp16 four at a time with only a few instructions.

As you would expect, using their smaller weights lets them run inference faster in the memory-bandwidth-bound regime (low batch sizes). Below, the x-axis is batch size in all cases.


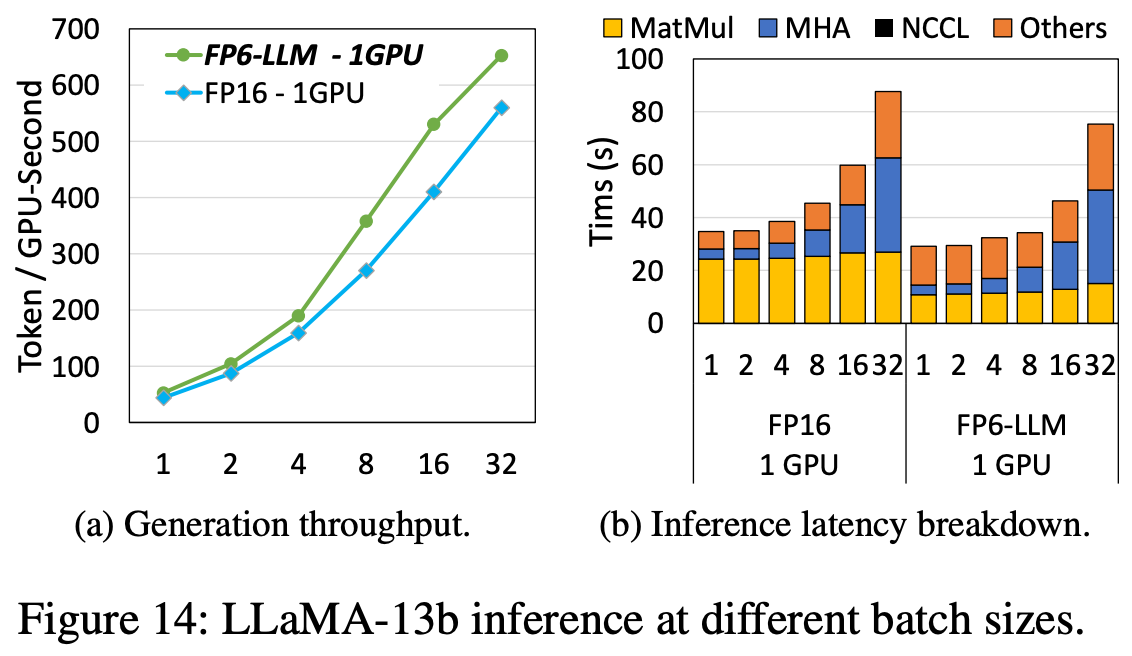
Since there are no model quality measurements here, it’s not clear how w6a16 inference compares to other configurations. But that’s fine—just getting the speed maxed out is already plenty of contribution for one paper.
Personally, I’m not sold on non-byte-aligned scalar quantization as the “right answer”—at that level of software complexity, you might as well be doing vector quantization. But since the new NVIDIA cards are going to support fp6, it certainly does make sense to see how well we can milk that.
If you want a more complete story behind my reduced newsletter output starting last fall, it’s a combination of:
Once we stopped being MosaicML and joined Databricks, I went from being a large fraction of our digital marketing to a tiny fraction. So the value to the company of writing this went down.
I started getting to do less research engineering and more research. This newsletter was the one thing making me feel like I was still a researcher during the heads-down building days, and once I was having fun doing research all week, I didn’t really want to stop and read papers.
I used to always enjoy reading papers, and feeling this looming obligation to write a newsletter every week sucked the joy out of it.
DBRX was all-consuming. We had so many pushes for so many intermediate deadlines starting in the fall, and it’s hard to spend a whole Sunday writing this while your coworkers are busting their butts building + debugging stuff for the team. Plus, 3072 H100s cost much more cash per day than I do per year, so it’s kind of hard to justify spending time on anything except getting the run working and adding training optimizations.
The official pronunciation is D-B-R-X. But me, Naveen, and various others are team D-B-Rex. Some of the people on our data team insist it’s “Da Bricks,” largely so that they can respond to code problems with “Did you try hitting it with Da Bricks?”
I got this framing from a paper like 10 years ago but have never been able to find it again. Please comment if you know which paper(s) came up with this.
Davis, I've loved reading your summaries and appreciate this latest on DBRX. However, I am wondering why you included this "Since OpenAI had GPT-3 before we even existed as a company, this indicates that the gap between the leaders and others is narrowing (as measured in time, not necessarily model capabilities)." Databricks has been around a lot longer than either OpenAI or GPT3 (2013), thus this note leaves me a bit confused.
Finally! You’re back! Now I can keep up with arxiv again :)