
2023-6-11 arXiv: Training on GPT outputs works worse than you think, but training on explanations works great

This newsletter made possible by MosaicML.
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Usually when people use existing LLMs to generate instruction tuning data, they just prompt the model with some input and treat its answer as the “true” output.

In this paper, they prompt the pretrained model to think step-by-step using an extra “system prompt” added before the regular prompt. They use this to generate an instruction tuning dataset with step-by-step explanations instead of just answers.
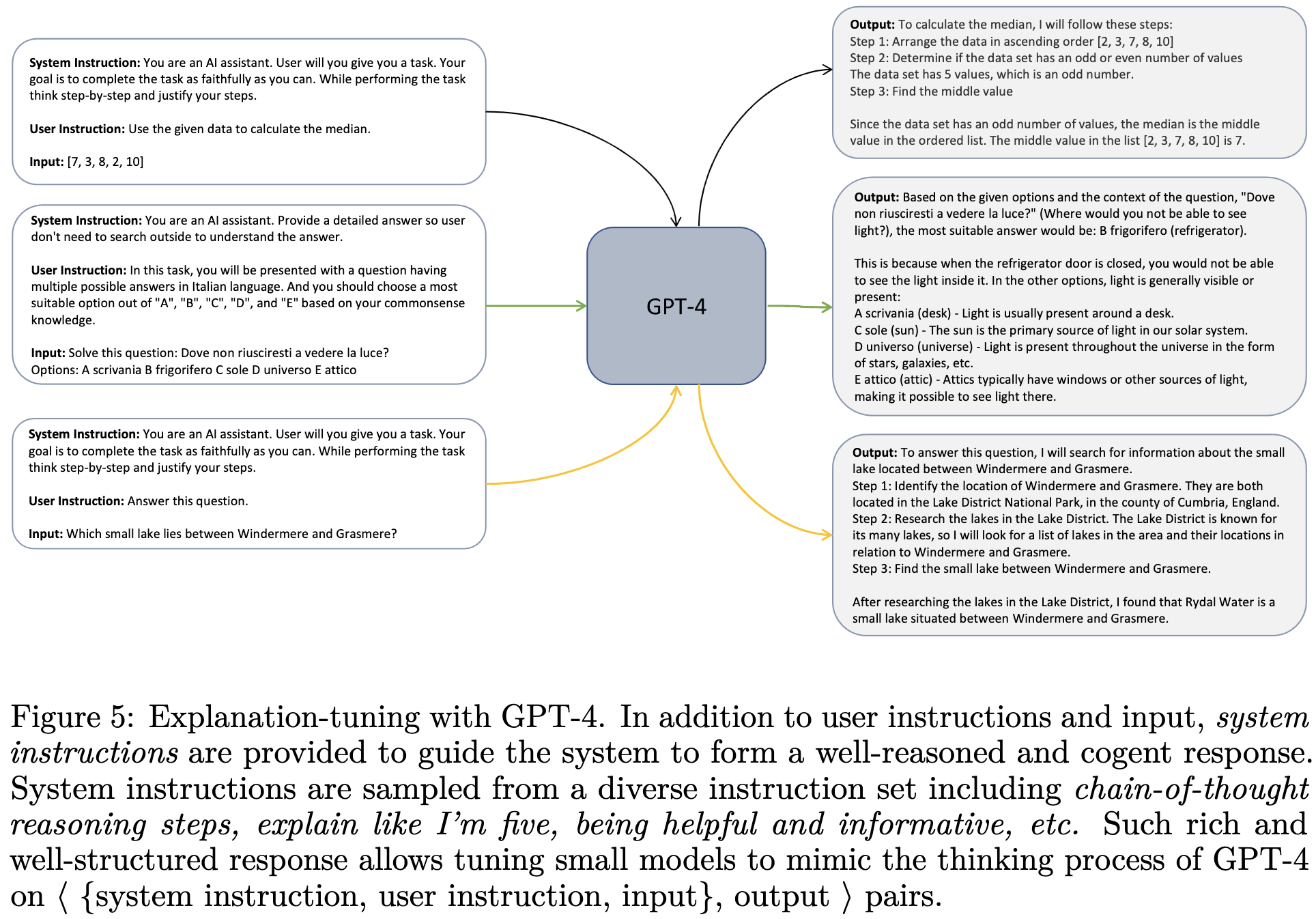
The system prompts they use are drawn from 16 handcrafted strings designed to elicit useful answers and explanations.

To get questions to ask the model, they sample from FLAN-v2.

When generating explanations, they send 5 million queries to ChatGPT and 1 million to GPT-4. This ratio was probably a consequence of cost and rate limit differences, and I’d assume you could do better sourcing (almost?) all your data from GPT-4.

Their “explanation-tuning” approach seems to yield a much better model than regular instruction tuning across a variety of different benchmarks.
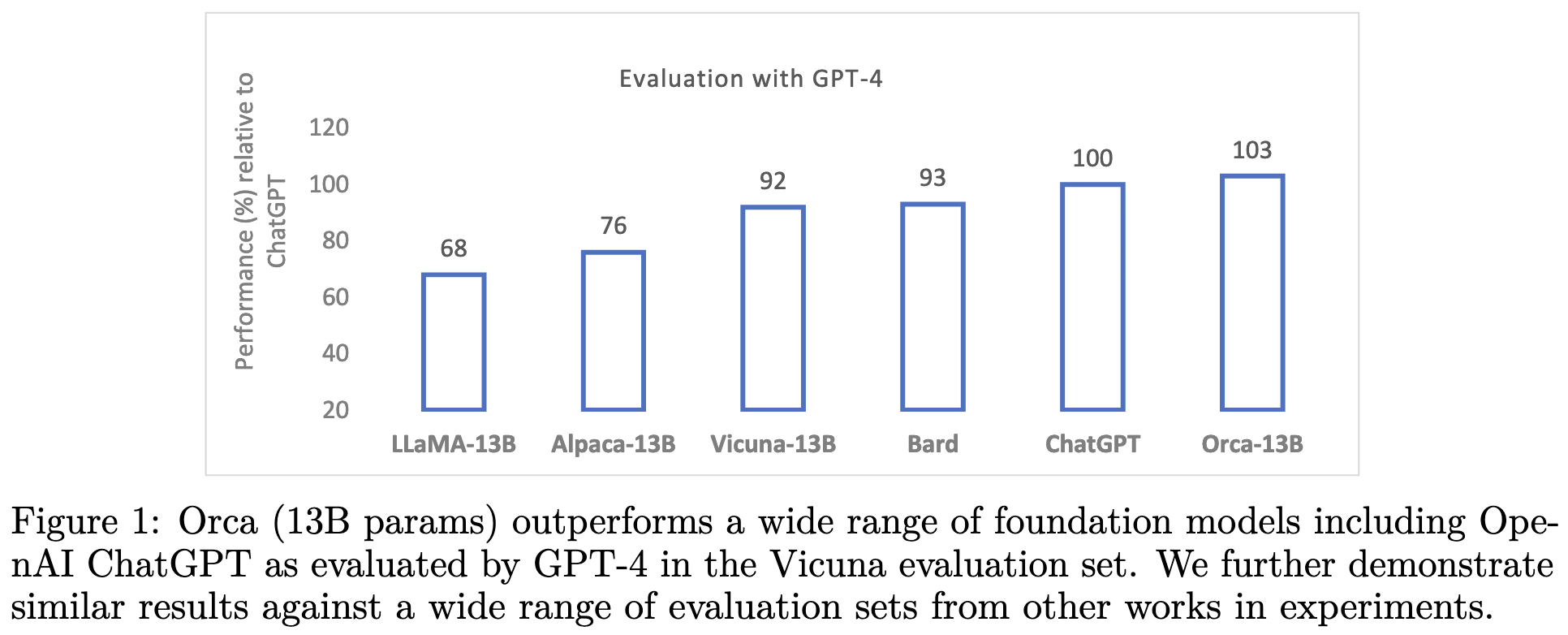


Nice to see empirical improvements that also make sense intuitively. I’m super curious how much of this lift comes from just having more tokens of supervision vs having step-by-step reasoning specifically.
The False Promise of Imitating Proprietary LLMs
If you finetune a base model on outputs from a high-quality LLM like ChatGPT, you get it to produce outputs that humans rate as better a lot of the time. But…

…the model is often just mimicking the style of ChatGPT without the factuality, and doesn’t necessarily improve as you finetune on more outputs.
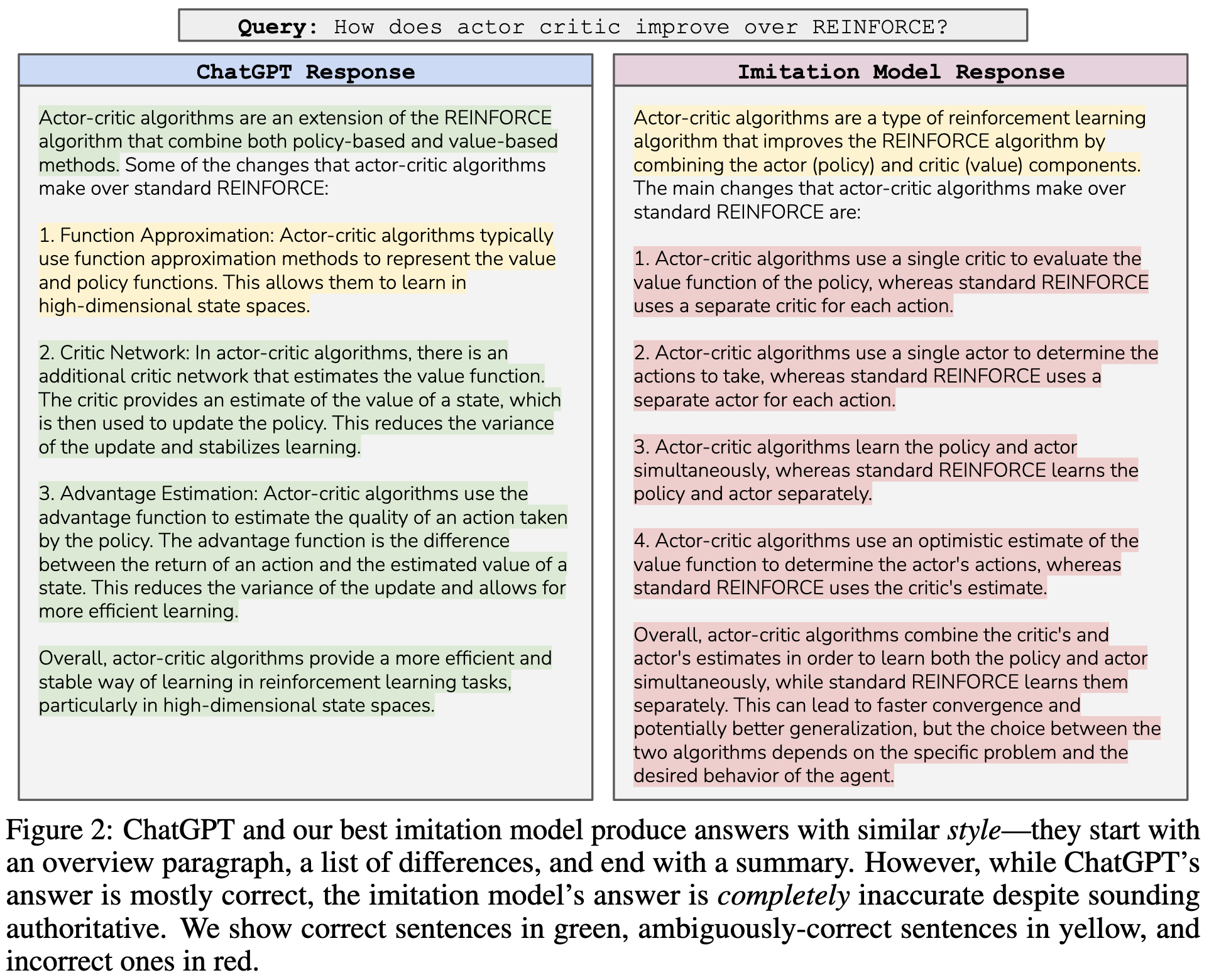
Also, the student model doesn’t get better as you train on more outputs from the pretrained model. Whereas it does get better with, e.g., model size.

Based on these and other experiments, they suggest that:
Finetuning a less-capable model on outputs from a more-capable model might just be training the former to hallucinate when it doesn’t have the requisite knowledge to answer the question.
Pretraining is most of what gives a model its capabilities, and finetuning just kind of elicits them, consistent with the superficial alignment hypothesis.
As a consequence of the above, model pretrainers like OpenAI have more of a technical moat than model finetuners—including people finetuning on pretrained model outputs.
They also note that these results don’t evaluate the impact of training strategies like RLHF; this means that these claims and those of the above Orca paper can both be true.
LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
Let’s say you don’t care about inference cost and you just want the best text generations you can possibly get. One approach to doing this is to ensemble the predictions from a bunch of different models. This is promising since which model gives the best answer can vary by input.

But one challenge here is that, unlike with classification, you can’t average strings. So to fuse the predictions for different models, they:
use pairwise comparisons of the individual models’ outputs to identify the top k outputs, and then
use a fusion model to combine these k outputs.
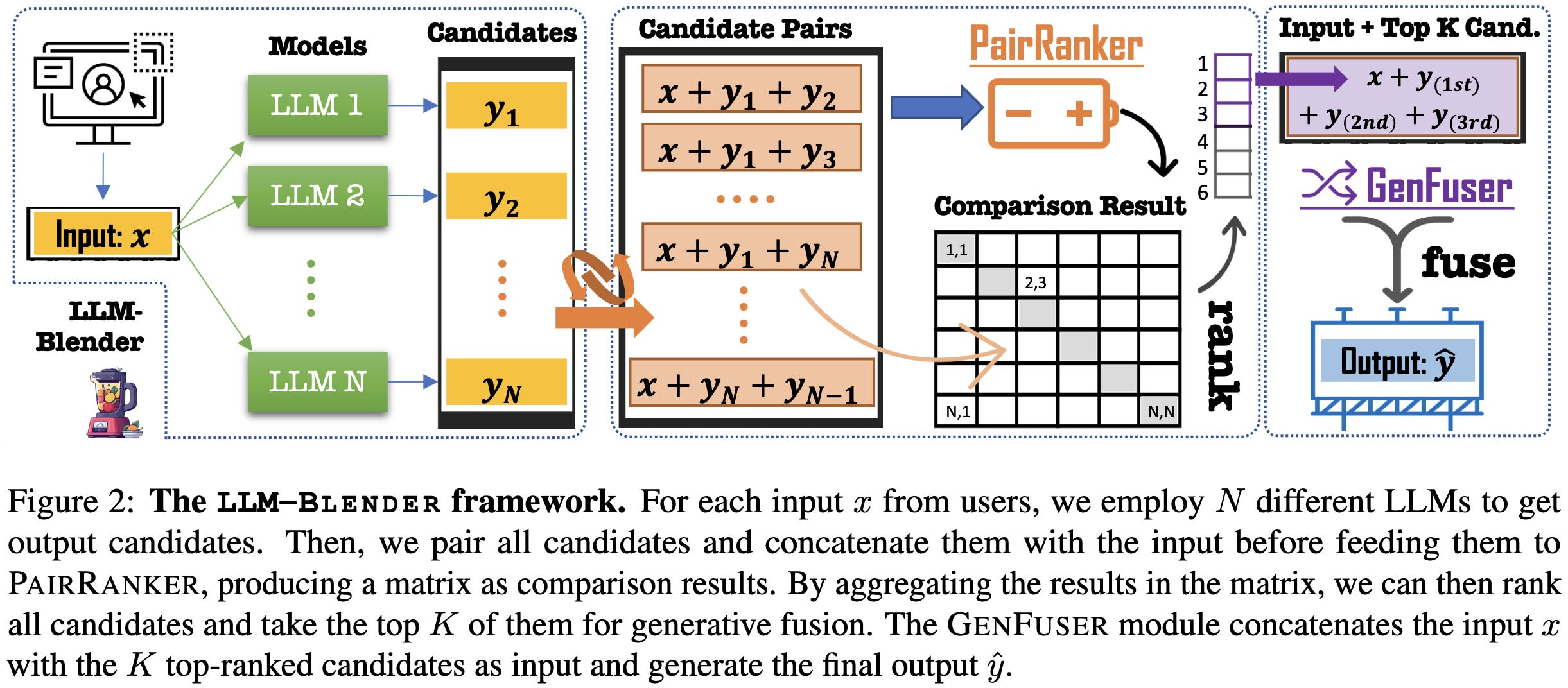
Seems to do much better than any individual model. Their reranking approach (PairRanker) also seems to beat existing alternatives most of the time.

What stuck out to me about this paper is how even the probabilities of being the best were across different models. This could help explain why cascading different models can yield higher accuracy than any individual model.
In other news, it’s odd that Flan-T5 was so rarely the best given results like this.
Resolving Interference When Merging Models
Suppose you want to merge different task-specific finetuned models derived from the same base model. This could be useful if you want to grab capabilities for your model à la carte or just generally make different models composable.
One approach to this is to just average the weights of the different models. This can work well, but they propose a way to do better.
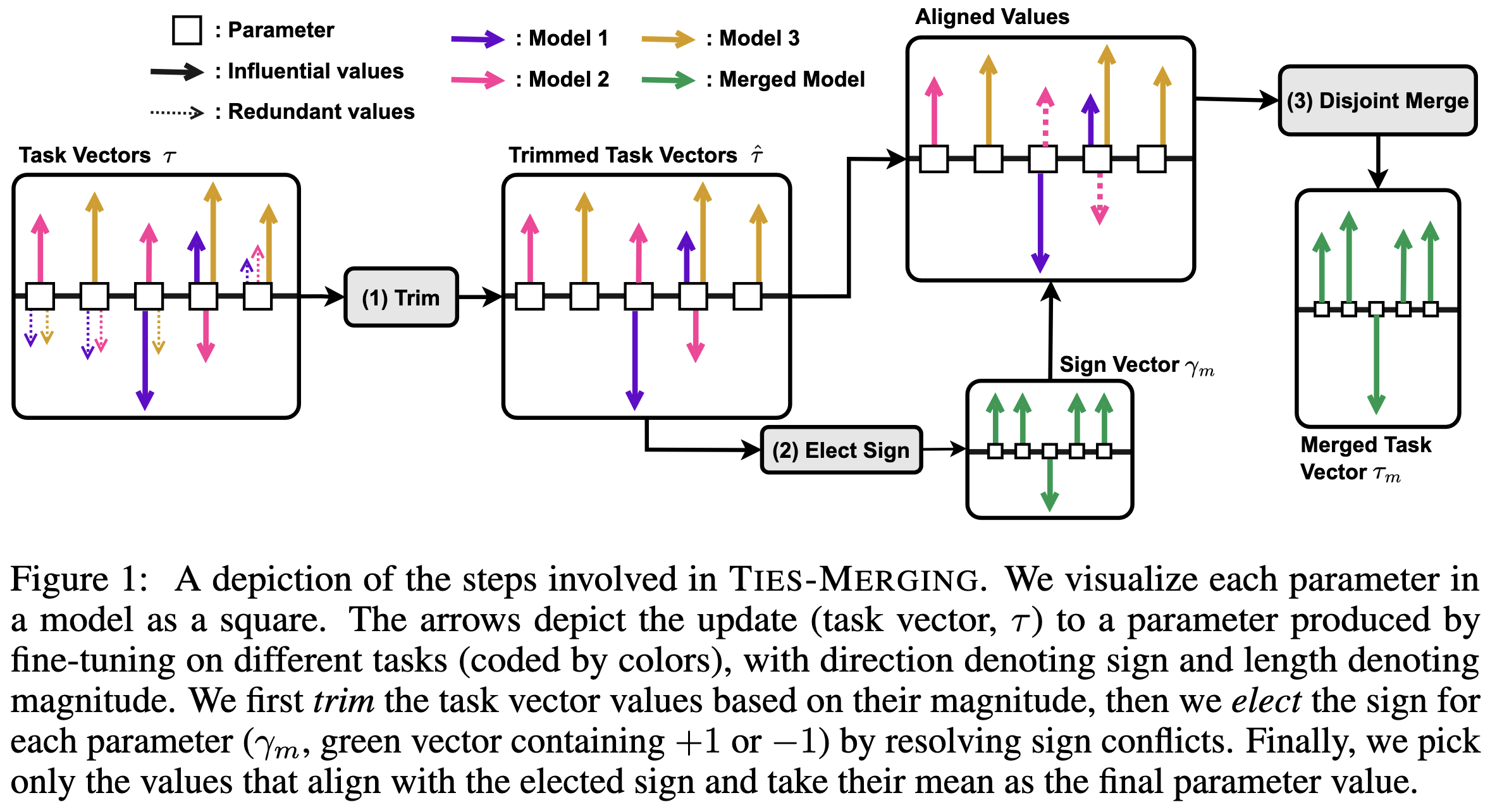
Their method:
Computes the elementwise difference between each model and the shared initial model. They differences are called “task vectors.”
Zeroes out the lowest-magnitude elements of each task vector
Computes a sign for each element by averaging the signs of that element across all task vectors
Computes a combined task vector by averaging across all partially-zeroed task vectors, but ignoring any vector that wanted a different sign for a given element
Adds this combined task vector to the original model


Seems to work better than other model merging approaches, including the more obvious solution of just averaging all the models.


Further, each step of their method seems to have a large impact.

This definitely violates my intuition for what should work, but that’s often a good thing in science. I would expect heuristics based on how sensitive the outputs are to each parameter to work the best, but their results suggest that thinking in terms of sign and large-magnitude-weight preservation is really effective.
Blockwise Parallel Transformer for Long Context Large Models
They built fast transformer kernels that often beat FlashAttention in terms of both speed and memory (see “Blockwise Parallel” vs “MemoryEfficient” rows below).

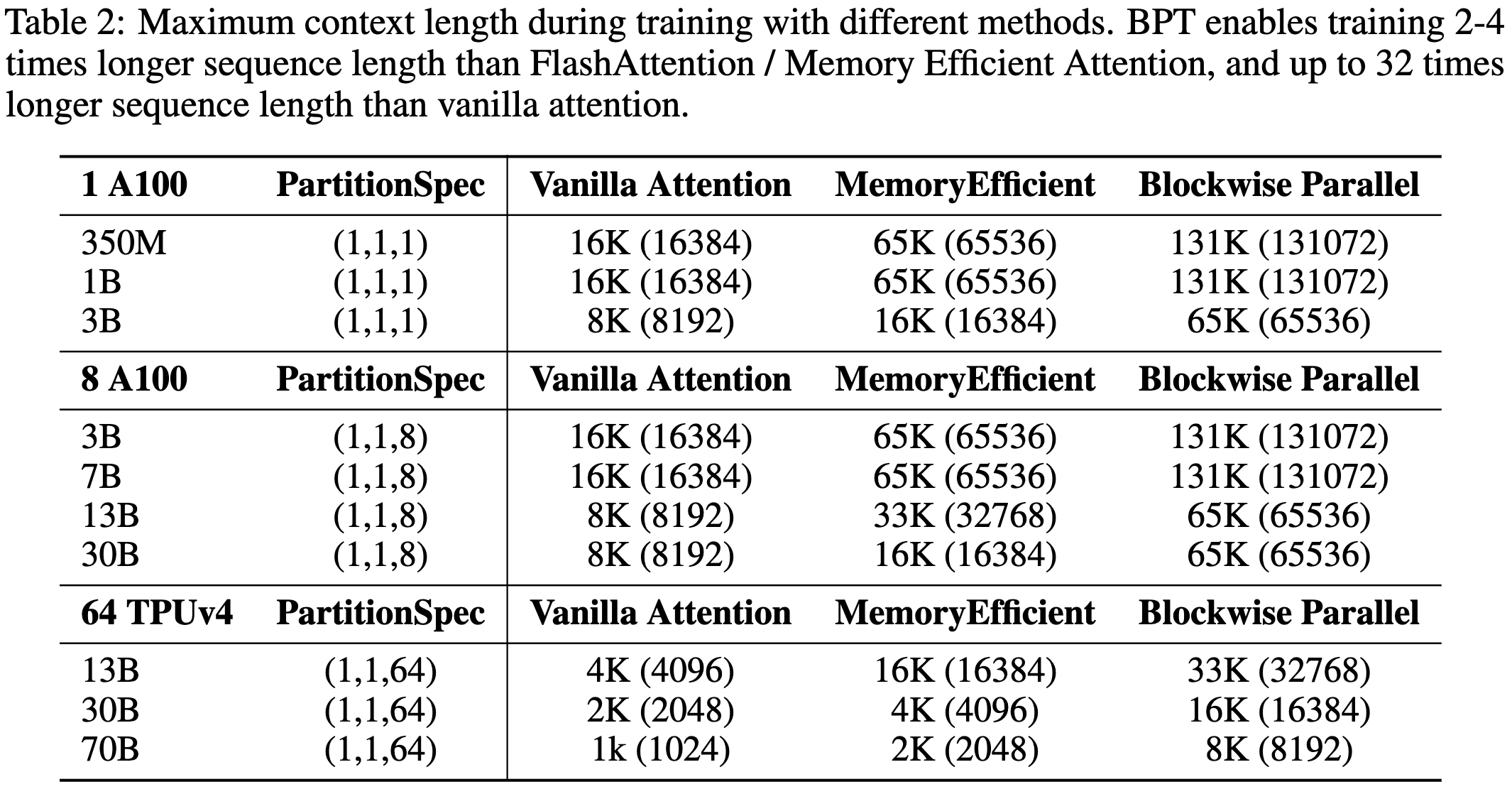
This is especially impressive because they implemented their approach in high-level JAX code, not low-level kernels.

The basic idea is to a) split the input sequence into disjoint subsequences and b) immediately run the attention output for a given block of tokens through the FFN, without stopping to wait for the attention op to finish for the rest of the tokens.

Will be fun to try this once someone ports it to PyTorch / CUDA / Triton.
A Quantitative Review on Language Model Efficiency Research
A meta-analysis in which they aggregated tons of reported results from different papers to try to understand the extent to which progress on various benchmark tasks is actually monotonic and agreed-upon.

The numbers seem to trend downward over time, but it’s definitely not the case that all claimed SotA results are actually the best reported when the paper comes out. It’s also not agreed-upon how well a given method works, with different papers getting different numbers (same color = same method, below).

Another entry for my big list of (usually troubling) ML meta-analyses.
Towards Anytime Classification in Early-Exit Architectures by Enforcing Conditional Monotonicity
When using early exits to abort partway through your forward pass at test time, you’d like your network’s accuracy to be monotonic in the fraction of the forward pass you do.
This doesn’t necessarily happen automatically. To make it happen, they build on the Hard Product-of-Experts method. This method has each successive classifier output boolean masks of which classes it thinks could be right, and computes the prediction-so-far as the elementwise AND of all the predictions-so-far. Since the probabilities are normalized by the number of nonzeros and the nonzero count can only decrease, you get guaranteed nondecreasing confidence in each class. This guarantees lower loss with depth as long as the true class is never discarded.

They relax this construction to use a product of ReLUs instead of a product of binary masks, which improves accuracy a lot.

By adding intermediate classifiers throughout the network, they can nearly preserve the original accuracy on ImageNet while skipping some (?) of the computation.

One nice property of their method is that you can stick it onto a pretrained model after the fact and it works basically just as well, except with respect to the probability calibration.
Gorilla: Large Language Model Connected with Massive APIs
They finetuned LLama to be really good at calling APIs.

By really good, I mean often better than GPT-4 and Claude, with and without retrieval augmentation.

The APIs being considered are model APIs from Hugging Face, TensorFlow Hub, and Torch Hub.

To get finetuning data, they used GPT-4 outputs prompted with self-instruct. When including retrieval in the example, they added "Use this API documentation for reference: <retrieved_API_doc_JSON>" to the prompt.
Since there are often multiple ways to write a correct program, they inspect whether the model called a suitable API by examining the abstract syntax tree of the output. If you construct a reference AST for each API call in your database with all arguments specified, correct API calls are always subtrees of some reference AST.
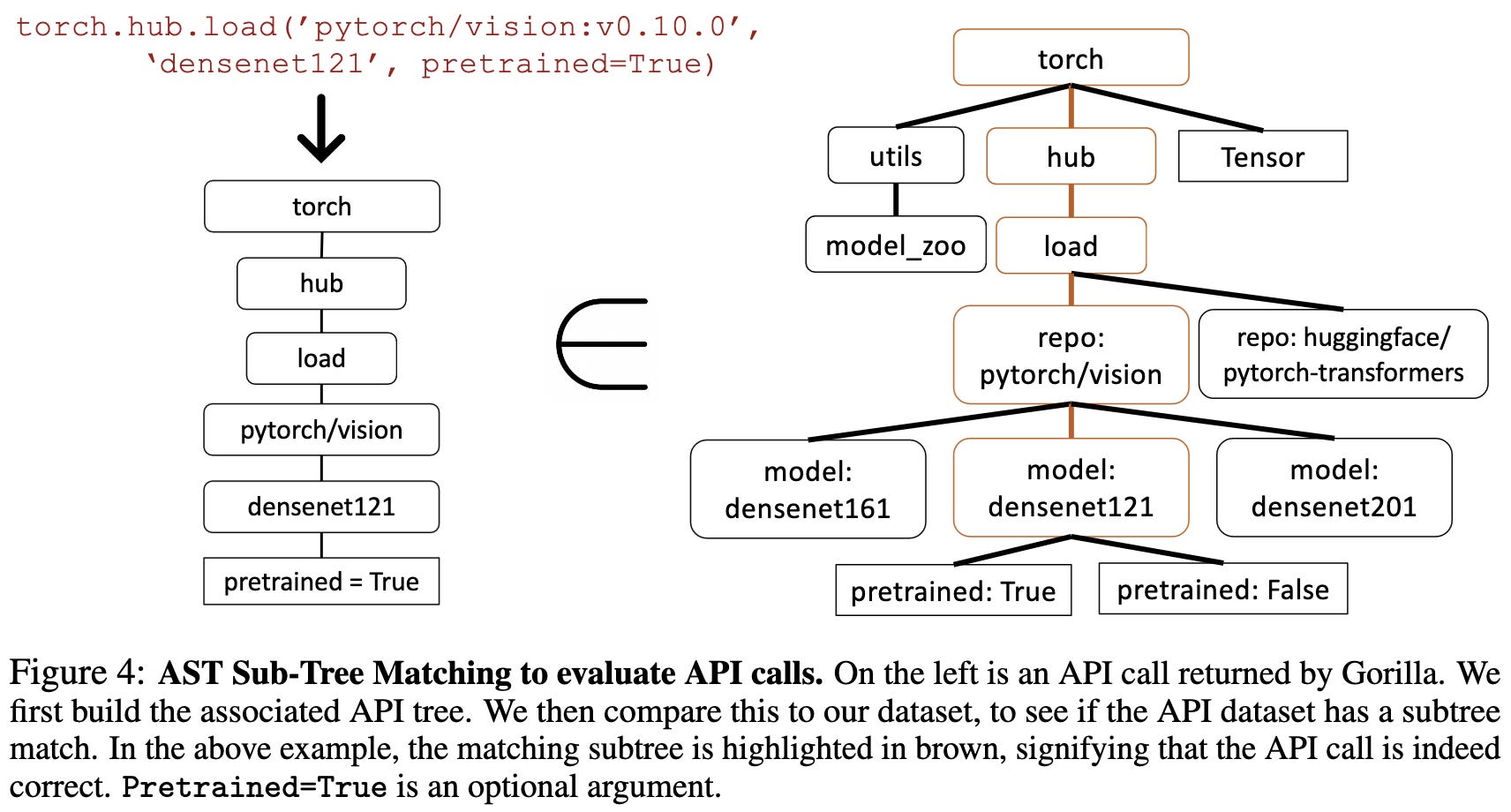
One cool consequence of training with retrieval results in the prompts is that the model can handle API changes as long as you show it an up-to-date example.

Also, they have a cool video showing how they can replace macOS spotlight:
The tool use literature is short on apples-to-apples comparisons, but this seems (?) like it might have the best results reported so far—especially when considering that their model is only 7B params.
Faster Training of Diffusion Models and Improved Density Estimation via Parallel Score Matching
Why have one diffusion model that operates at all noise levels when you could train different models for different noise levels in parallel and then chain them together at test time?


This strategy seems to beat the standard approach (denoted “SA-DPM”) when holding number of diffusion steps constant.

Though the extreme case of having one model per diffusion step (“DPSM”) doesn’t seem better than having 10 or 100 models.

Seems to be a much worse deal in terms of total training compute and param count, but a better deal in terms of inference compute—which could be valuable.
If this held training compute constant, it would also be an interesting datapoint regarding whether just scaling up param count is helpful outside of MoE models.
Human-imperceptible, Machine-recognizable Images
If your threat model is humans being able to manually inspect your images, you can do privacy-preserving training by systematically messing up your images in ways that (modified) ViTs can still deal with.
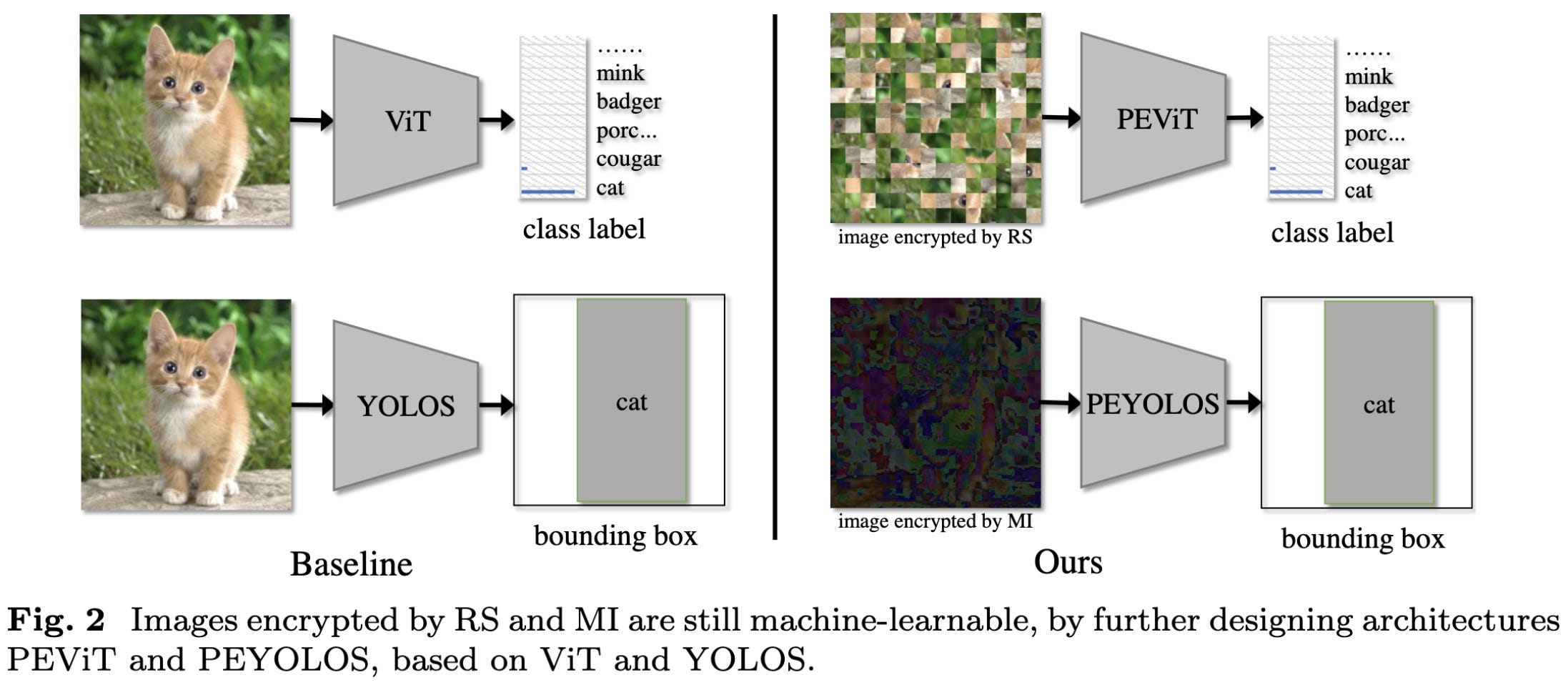

At least with the right training settings, this doesn’t cause that severe an accuracy drop.

It also doesn’t slow down inference much.

Existing reconstruction methods don’t manage to invert their image shuffling. Though of course this isn’t exactly a formal privacy guarantee.

I personally wouldn’t be satisfied with this level of privacy, but it’s always great to see work thinking creatively about tradeoffs and threat models. Even a little privacy is better than the current default of none, and something like this might be easier to adopt than, e.g., secure multiparty computation—especially since it could let you just obfuscate the data at the point of collection and be done.
Information Flow Control in Machine Learning through Modular Model Architecture
They train an MoE model where certain data is only allowed to cause param updates for certain experts. At test time, only certain experts are available to certain users.
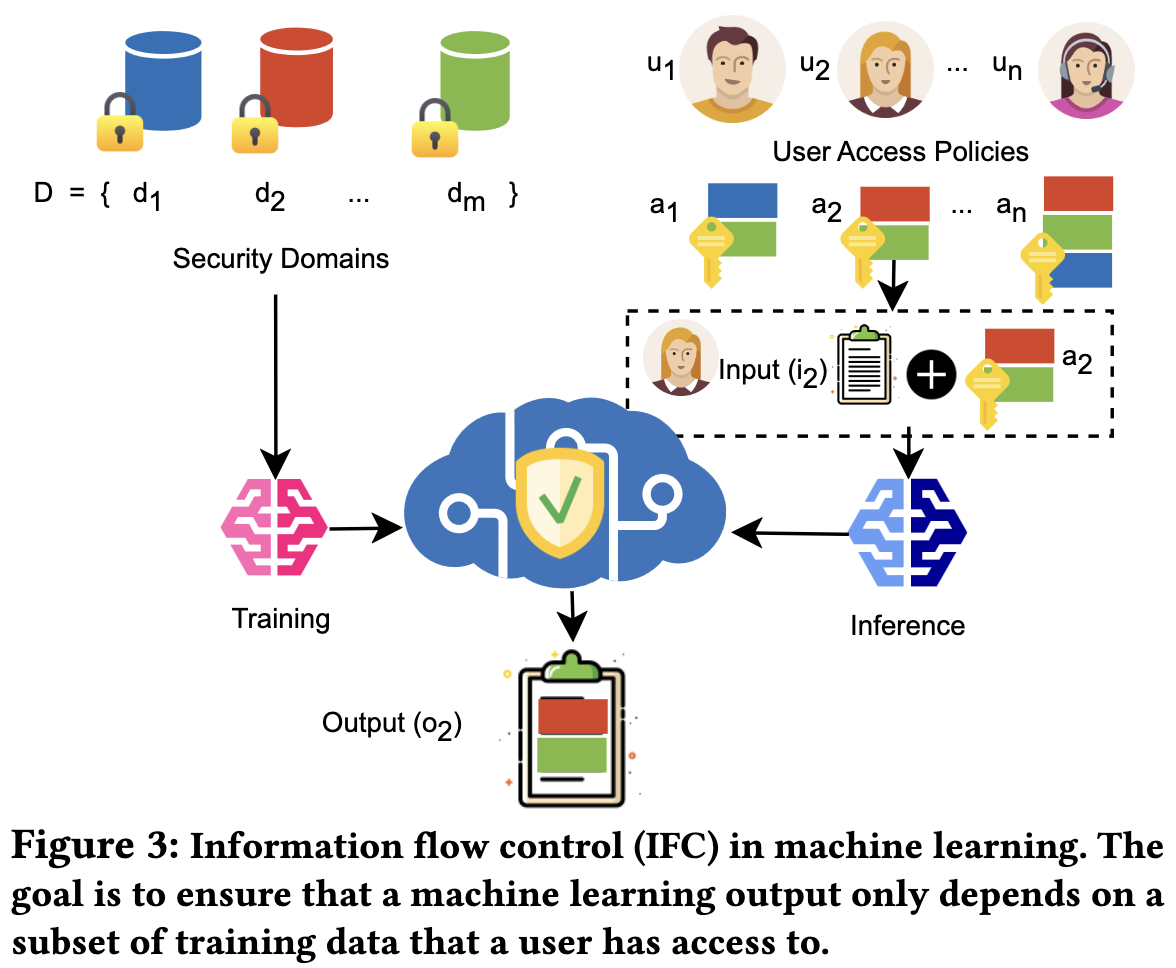

I gave up on following the private ML literature, but this seems like an interesting new take on the problem.
Has the Machine Learning Review Process Become More Arbitrary as the Field Has Grown? The NeurIPS 2021 Consistency Experiment
No, but a correlation of <.6 between groups of reviewers is pretty terrible. Especially since those scores are already averaged across several reviewers, which should decrease the variance.

You can slice the results a bunch of different ways but they’re all depressing. Or maybe relieving if you just got a paper rejected.



Inference-Time Intervention: Eliciting Truthful Answers from a Language Model
Instead of engineering their prompts or finetuning their model, they perturb their activations at test time in a direction that separates the activations from positive and negative examples two classes on a small validation set. In particular, they identify “truthful” directions using the TruthfulQA dataset and perturb activations to make the outputs more truthful.

The perturbations only apply to the top-k attention heads that have the most correlation with truthfulness.

They only use some heads since heads vary widely in correlation with truthfulness.

This direct perturbation of activations seems to work much better than few-shot prompting or finetuning on the same (small) amount of data.


At least if you tune the hparams well enough.

Interestingly, their intervention is most helpful for answers pertaining to logical falsehood (leftmost bars). This suggests that the model “knows” statements are false but doesn’t manage to incorporate this into its output.

They focus on truthfulness here, but I could see direct activation perturbation being a general purpose alternative (or supplement?) to inc-context learning + prompt engineering.
At least intuitively, I’d expect it to offer more control of and confidence in the model’s outputs; like if someone wanted to control my behavior, sticking chemicals or electrodes in my brain would probably be more robust than just talking to me in the right way. This also feels promising for deceptive alignment, and maybe alignment more generally.
Soft Merging of Experts with Adaptive Routing
Suppose you’re doing MoE with routing at the granularity of entire inputs rather than individual tokens. Instead of picking one expert per input and weighting its output by the routing weight, they propose to just do a weighted sum of the experts to compute an input-specific parameter matrix, where the weights in the sum are the routing weights.

This adds a memory-bound sum operation before each MoE linear, but is just a batched matmul after that—so it should still get high GPU utilization if your individual inputs are large enough.
This approach seems to lift accuracy with minimal reduction in throughput.

This paper increases my conviction about a couple phenomena:
The finding that scaling up from 8 to 16 experts doesn’t help GLUE finetuning is consistent with my mental model that more experts only help when you [pre]train on enough data to get each expert well-trained. Although this is weak evidence for that claim since there wasn’t a clear correlation between GLUE dataset size and accuracy.
Dynamic-weight-generation approaches actually work. We’ve seen this with GigaGan, Dynamic Convolution, and Dynamic Convolution (yes, there’s a name conflict).
As a generalization of 2, multiplicative interactions are useful.
Normalization Layers Are All That Sharpness-Aware Minimization Needs
SAM works better if you just use it on the params from the normalization layers, and worse if you use it on everything except these params. Though you might need to increase your SAM perturbation size in the former case to get the benefits.



Only perturbing the normalization params also saves some compute time since you can skip most of the weight gradient computations.

It seems to be important to perturb the normalization parameters specifically, as opposed to any old small set of parameters.

The longer you use SAM during training, the more it matters to only apply it to the normalization params; this fits with the hypothesis that doing it this way is just plain better.

Not clear if it’s causal, but SAM on just the normalization params increases the BatchNorm scales and shifts BatchNorm offsets towards zero.

This is both an interesting set of datapoints and apparently an actionable improvement to training. Always great to see both in one paper.
Don't trust your eyes: on the (un)reliability of feature visualizations
First, you can adversarially mess with your model to make activation-maximizing feature visualizations resemble arbitrary images.


Second, even in the non-adversarial case, your feature visualizations aren’t necessarily too meaningful.

And third, they have some proofs about the limitations of feature visualization methods.

A detailed but discouraging analysis of a common practice.
On the Reliability of Watermarks for Large Language Models
Can you remove the watermark in AI-generated text by just paraphrasing the text?
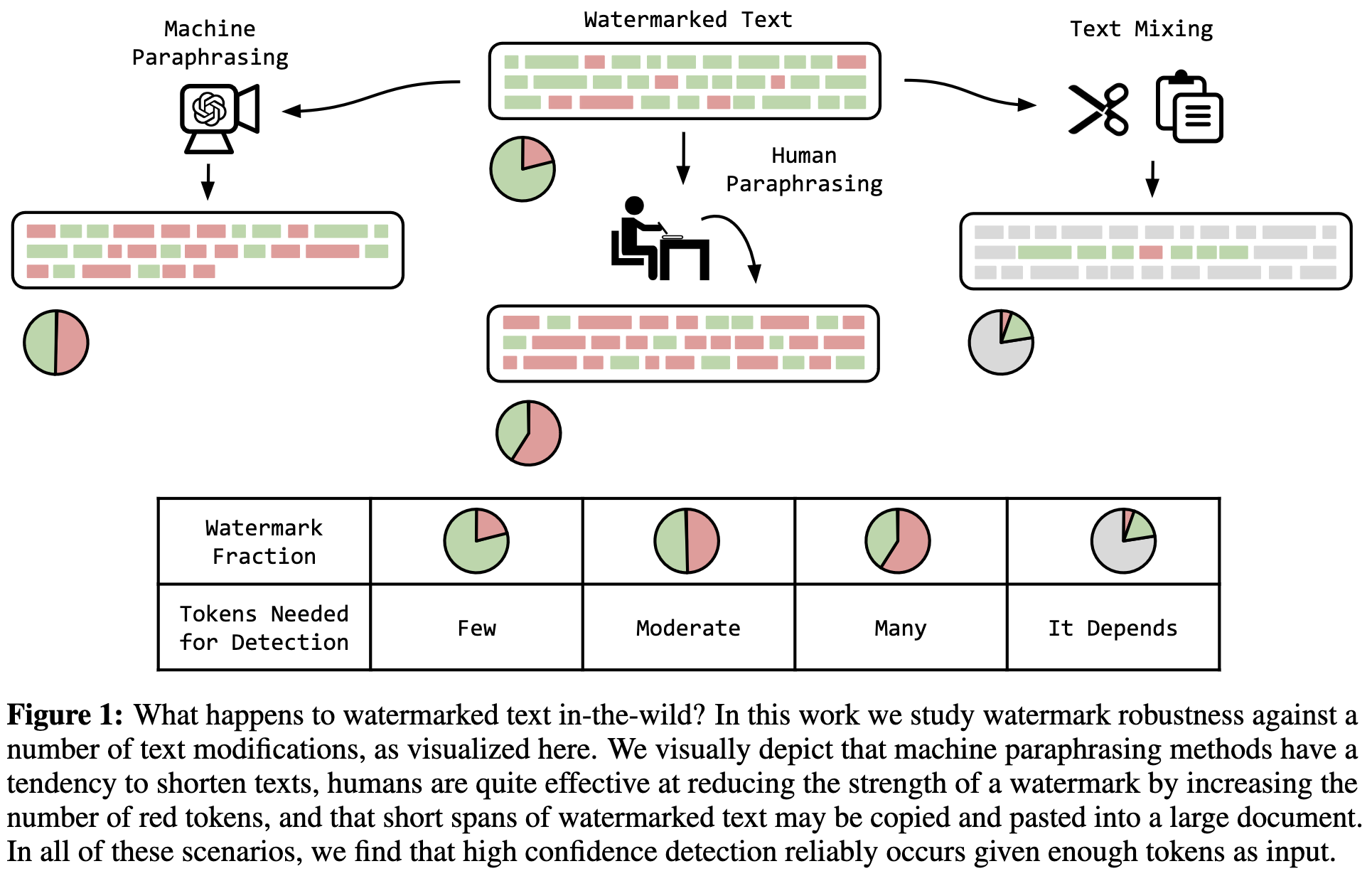
With some watermarking schemes, the answer is yes. You can just paraphrase the text and then the rolling hashes change and the watermark goes away. This paper fixes this by hashing in smaller windows, letting you detect suspiciously frequent token n-grams even if the surrounding text is changed.

With this modified watermarking scheme, you can still detect AI-generated text even after another model paraphrases it, provided that you have a long enough passage of text. This works because the paraphrase will recycle words and snippets from the original text more than you’d expect by chance.

The same pattern holds when the paraphrasing is done by motivated grad students rather than GPT variants.

Seems the detection-evasion pendulum just swung back in favor of the detectors. Will be fun to watch this arms race play out over the next couple years.
On the Design Fundamentals of Diffusion Models: A Survey
A nice overview of different choices one can make when designing + training a diffusion model.

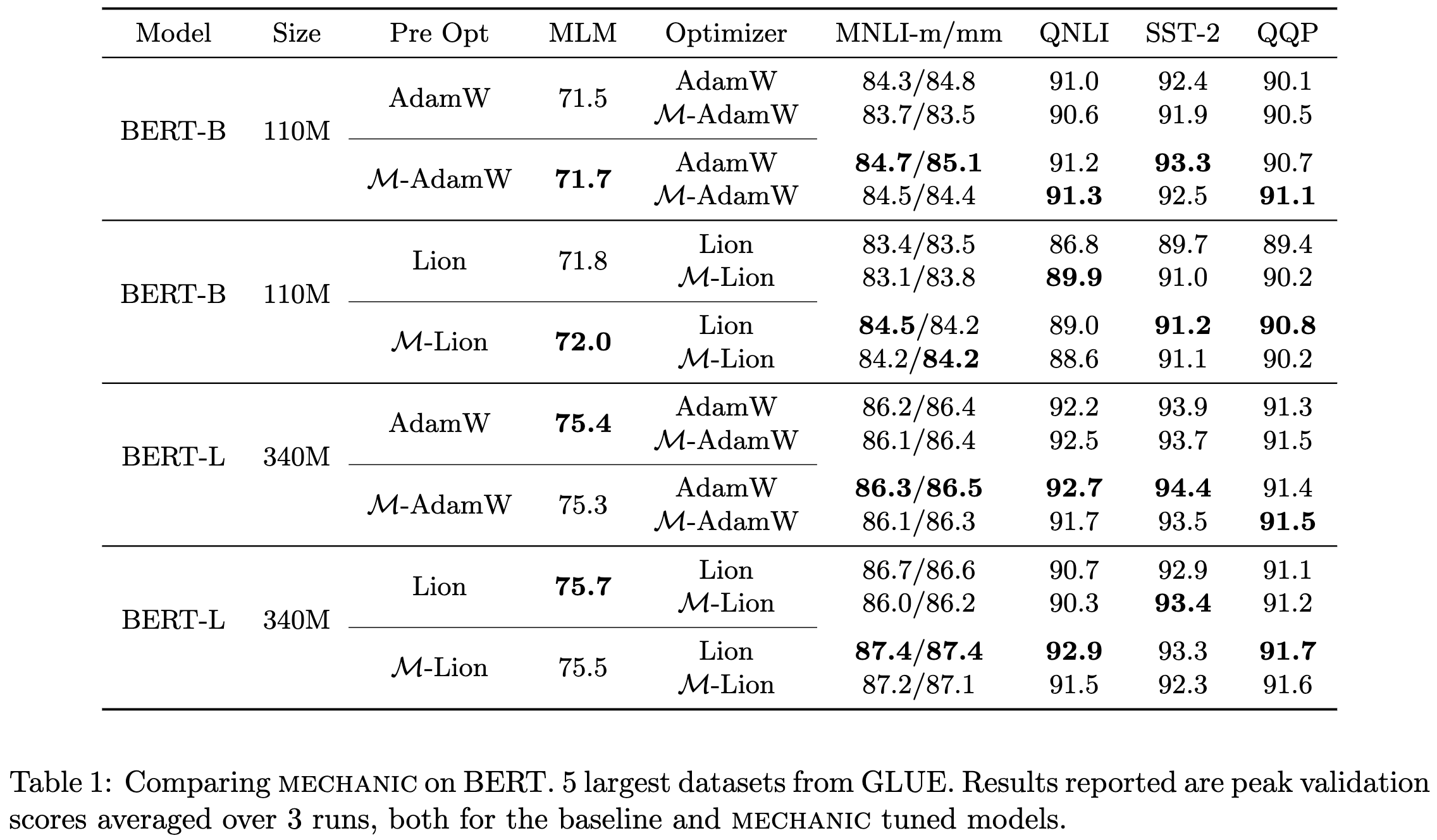
Mechanic: A Learning Rate Tuner
They introduce an algorithm for automatically setting the learning rate to use for a given step.

It seems to work on par with tuned learning rates + learning rate schedules taken from other papers.

This holds both for BERT finetuning and image classifier finetuning.

Would certainly be cool to remove the need to manually set learning rates.
How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
A big, systematic study of different instruction tuning datasets and evaluation strategies.

First, they find that different datasets help or hurt performance on different tasks. And using a good mix of data sources can help you do a lot better both on particular tasks and overall across tasks.

Better initial models remain better after instruction tuning.

Smaller models benefit more from instruction tuning than larger ones.

Here’s a fun finding: using GPT-4 to evaluate your model output may be mostly measuring how many unique tokens there are in the output.

Using humans to evaluate your outputs directly doesn’t seem to hit this issue; humans rank models roughly in accordance with their performance on benchmark tasks.
Interestingly, using only human-authored examples doesn’t work as well as using a combination of human- and AI-authored examples.

Worth a detailed read for anyone interested in instruction tuning.
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
Tl;dr: they applied Patched Frame of Reference (PFOR) compression to LLM weights, though with a scale factor per block in addition to an offset since the input is floating point and needs to be rescaled. The weights are decompressed back to 16 bit floats before being used in a given operation.

In more detail, they:
Quantize most of the weights to 3 or 4 bits. This is done in chunks of 8 to 32 scalars, with the min and max values of each chunk used to normalize the values to the range [-8, 7] (for 3 bits) or [-16, 15] (for 4 bits).
Quantize the arrays of min and max values in the same way, but with a chunk size of 16. The offsets + scales for these arrays are 16-bit floats.
Store the values of “outliers” separately as a sparse matrix with 16-bit values and a custom CSR-like format. Outliers are determined by thresholding the “sensitivity” of weights, measured using an approximate inverse Hessian.

This approach can almost match the perplexity of unquantized models while using <5 bits per parameter.


With more weights included as outliers, you might be able to do even better. Relatedly, it seems to be important to allow individual weights to be outliers, as opposed to whole rows or columns.

What I think is coolest about this is that the memory savings are enough to compensate for the quantization overhead on an A100, letting them run faster than a 16-bit model. This might be enough of a speedup to be worth the perplexity hit even if you don’t care about space—especially on smaller models. Though I’m not sure how this compares to int8 inference.

These are strong empirical results. I’m especially surprised by the wall-time improvements; quantizing your headers and separately handling outliers both add overhead, so I would have expected this to be slower than the fp16 baseline.
Also, this paper makes me confident we can get to even lower precision by adding further optimizations:
At low bit widths, you can have each integer represent an index into a lookup table instead of requiring them to represent uniformly-spaced quantization bins. This doesn’t work as well at high bitwidths because the tables are too large to fit in registers, but is strictly more expressive when you can get away with it. Interestingly, this is how fast similarity search works on CPUs in libraries like FAISS and SCaNN.
The above is especially powerful with scalar quantization because you can solve k-means optimally in 1-D, meaning you can get optimal quantization bins. Though see this discussion.
You can introduce “compulsory” outliers at least once every 2^B elements for some bitwidth B. This lets you store your outlier indices using just B bits. You’ll have some interesting tradeoffs on GPUs though due to random access helping parallelism; and it won’t be worth it if your outliers are rare or high-bitwidth enough. (see PFOR)
You can store the high bits of the outlier values in the dense quantized version, so you only need to store the low bits in the outliers array. (see NewPFD/OptPFD)
If you really want to trade space for compute cycles, you can take your bitpacked representation and run it through a real compression algorithm like LZ4. Just piping everything through Huff0 worked surprisingly well for me.
And most importantly, preprocessing values with invertible functions before quantizing/compressing them. For a lot of numeric data, you’d be amazed how much mileage you can get out of just delta coding and then running the results through Zstd.
Wrote more than I intended to there, but the point is that we have room to do even better just using known techniques; so we should be optimistic about low-bitwidth quantization continuing to improve in the next couple years.