
2023-2-19 arXiv roundup: ICML deluge part 2

This newsletter made possible by MosaicML. This one’s a little delayed because it turns out combing through 1384 papers takes a while.
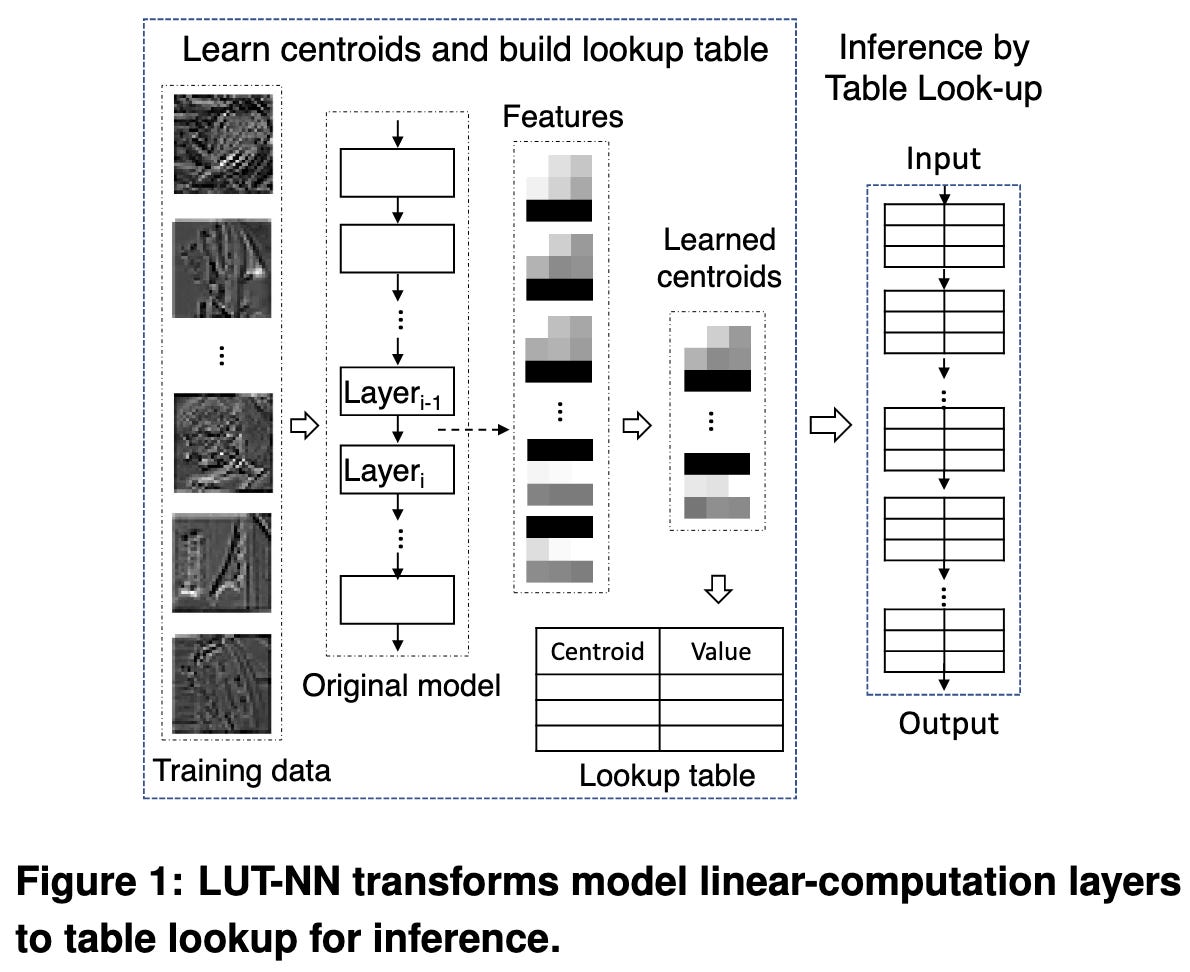
LUT-NN: Towards Unified Neural Network Inference by Table Lookup
Product quantization (PQ) variants have dominated similarity search for over a decade, and recent work has shown that you can also use PQ to speed up matrix multiplication. But no one has gone from speeding up individual matrix products to speeding up a full network with decent accuracy.
Until now.
Recall that the idea of product quantization is to precompute a lot of inner products so that you can just do a small number of table lookups at runtime instead of a large number of multiply adds. See my explanation here for more info.
To apply this to a neural net, the authors treat each token/pixel in an activation matrix as a sum of centroids, and look up the precomputed inner products between the network’s weights and the centroids.

To make this fast, they do a bunch of low-level optimizations, such as keeping the centroids in registers and traversing the centroids in an order that minimizes read-after-write data dependencies.
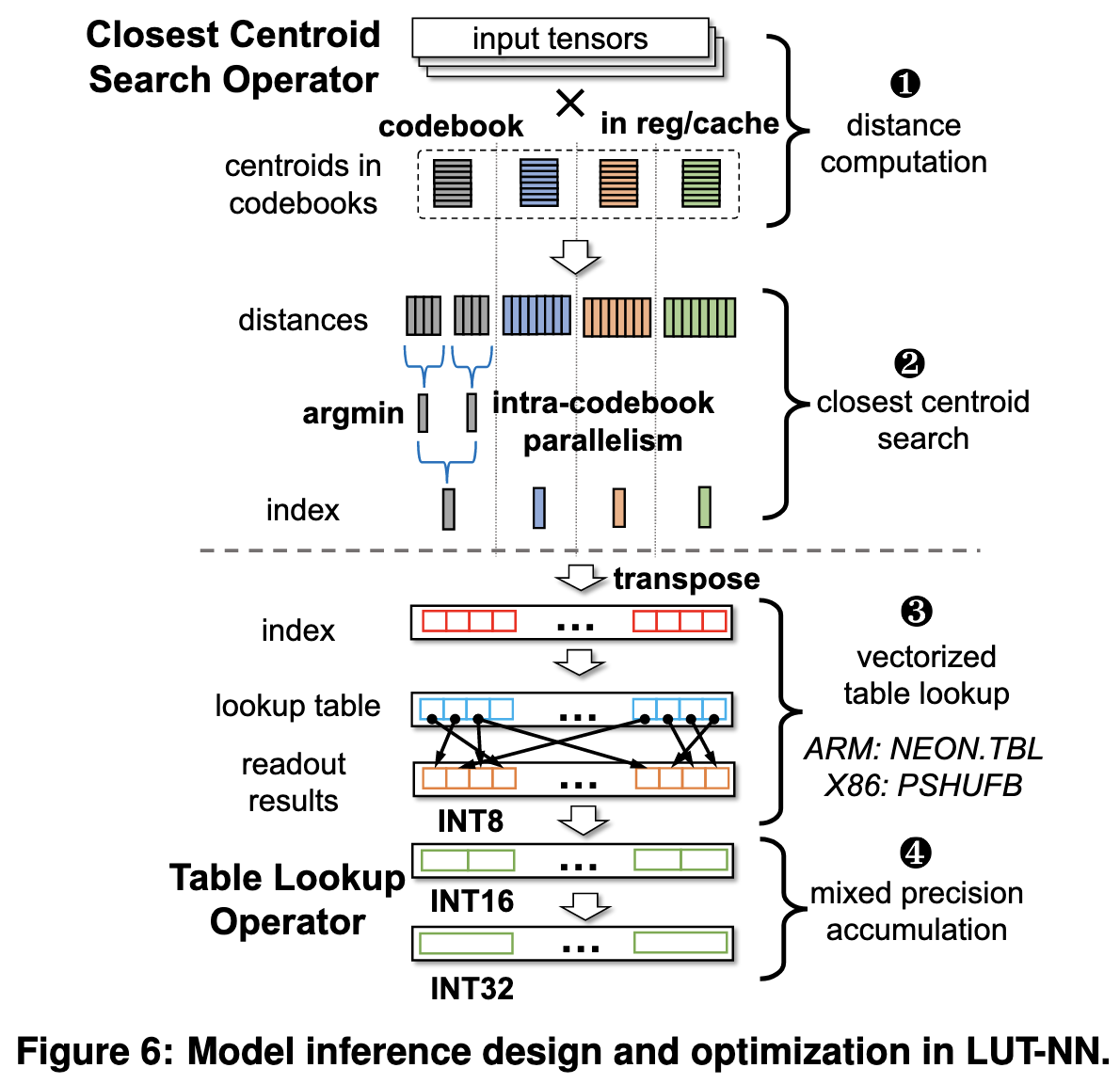
Since it’s important to get good centroids, they relax hard centroid assignment during training into soft assignment using a softmax with a differentiable temperature.

They evaluate this approach on BERT finetuning and image classification. It attains lower accuracy than the baseline networks, but way better accuracy than binarization (the next best option). It also does way better than just approximating individual linear/conv layers in isolation using my matmul algorithm (MADDNESS). This gap shows that the end-to-end training is essential.


From a speed perspective, they get 2-7x wall time speedups on real CPUs. This is super impressive for three reasons.
Modern CPUs have dedicated hardware for the (dense) baselines, but not their method.
TVM and the ONNX runtime have had way more engineering effort pumped into them than the authors’ research code.
The results get better and better as model size increases. This suggests that 7x might be pessimistic as model sizes grow.

They also perform some ablations to show that learning the softmax temperature is helpful.

Finally, they observe that it matters a lot which layers you replace. Since quantization error in the early layers can get amplified as you progress deeper into the network, you do way better replacing suffixes of the network and leaving the early layers unchanged.

This is super cool. I’ve been convinced we could get dramatic CPU inference speedups with vector quantization ever since I saw the first timing results from MADDNESS—but no one had gotten it working well for deep learning until now. There were great results in terms of FLOPs or model size for PQ variants, but not wall time.
There are a ton of implications here. First, I’m pretty convinced that network binarization is just going to go away. You can implement it as a special case of table lookups so it gives you strictly less model capacity and no speed advantage1, except maybe on GPUs with int1 tensor cores.2
Second, it suggests that hardware vendors might start rolling out systolic array support for lookup-adds like they have for multiply-adds. We’ll likely need a few more papers proving this out before it gets on the roadmap, but I expect those paper will get written in the next couple years.
Most speculatively, it suggests that the quest to quantize networks more and more might not have to stop at 1 bit. With good enough vector quantization, we could in theory get sub-bit quantization, with B bits in the compressed space encoding more than B model parameters.
SparseProp: Efficient Sparse Backpropagation for Faster Training of Neural Networks
They built fast backprop for unstructured sparse model training on CPUs.

At sufficiently high levels of sparsity, it’s faster than dense backprop.

The breakeven point is a bit worse when using multiple cores rather than a single one.

There are definitely accuracy losses compared to dense training, but they’re not horrible.

You’re probably not going to train anything serious on a CPU (unless maybe you’re doing federated learning) but it’s a cool proof-of-concept and a well-thought-out algorithm.
UniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models
What if we skipped most of the diffusion steps by just extrapolating from previous steps and then correcting the extrapolations?

There’s a bunch of math to get this right, but turns out you can use this idea to get better images after fewer diffusion steps.

A cool example of the classic principle that fitting residuals from a simpler predictor often works better than predicting targets directly.
Knowledge is a Region in Weight Space for Fine-tuned Language Models
If you fine-tune a model multiple times, all the copies that do well end up in the same region of parameter space.

Even more strongly, other models in the same region (found via linear interpolation) also do well—sometimes even better.


This is consistent with findings in model soups, lottery pools, branch-train-merge, model patching, and more. Linear mode connectivity seems to be a real thing a lot of the time.
Also, the fact that the loss can be even lower between different models supports that idea that optimization is prevented from descending all the way to the minimum by increasing curvature, which is consistent with our observation that learning rate changes pretty directly drive the loss.
The Edge of Orthogonality: A Simple View of What Makes BYOL Tick
Why does Bootstrap Your Own Latent work? Using linear algebra and some minimal assumptions, they show that having a linear predictor network + stop gradient operations makes the optimal predictor matrix roughly an orthogonal projection.

Using closed-form updates to the output head based on their derivations can improve accuracy.

Reducing Nearest Neighbor Training Sets Optimally and Exactly
How well can you prune your dataset when using a KNN classifier while provably preserving all the predictions? If your data is one-dimensional, pretty well—you can find a minimal data subset in polynomial time. If your data is more than one-dimensional, the problem is NP-complete, so…good luck.

Theory of Mind May Have Spontaneously Emerged in Large Language Models
If you give large language models classic theory of mind tests, they do pretty well—but only as of late 2022. GPT-text-davinci 002 was bad at this while ChatGPT does about as well as nine-year-olds.

Sketchy: Memory-efficient Adaptive Regularization with Frequent Directions
They reduce the size of the preconditioning matrices used in second-order optimization via the frequent directions sketch.


Adding their sketching approach tends to make second-order optimizers work a littie worse in terms of accuracy vs steps, but this might be worth it for the efficiency gain.

Also, I like this experiment they did. By examining the learned preconditioning matrices, they can estimate the effective dimensionality of the gradients across different networks and time steps. It’s on the order of dozens and fairly stable within a network.

ZipLM: Hardware-Aware Structured Pruning of Language Models
I really liked the CoFi paper and this one does even better, obtaining a significant improvement in the inference time vs accuracy tradeoff curve.
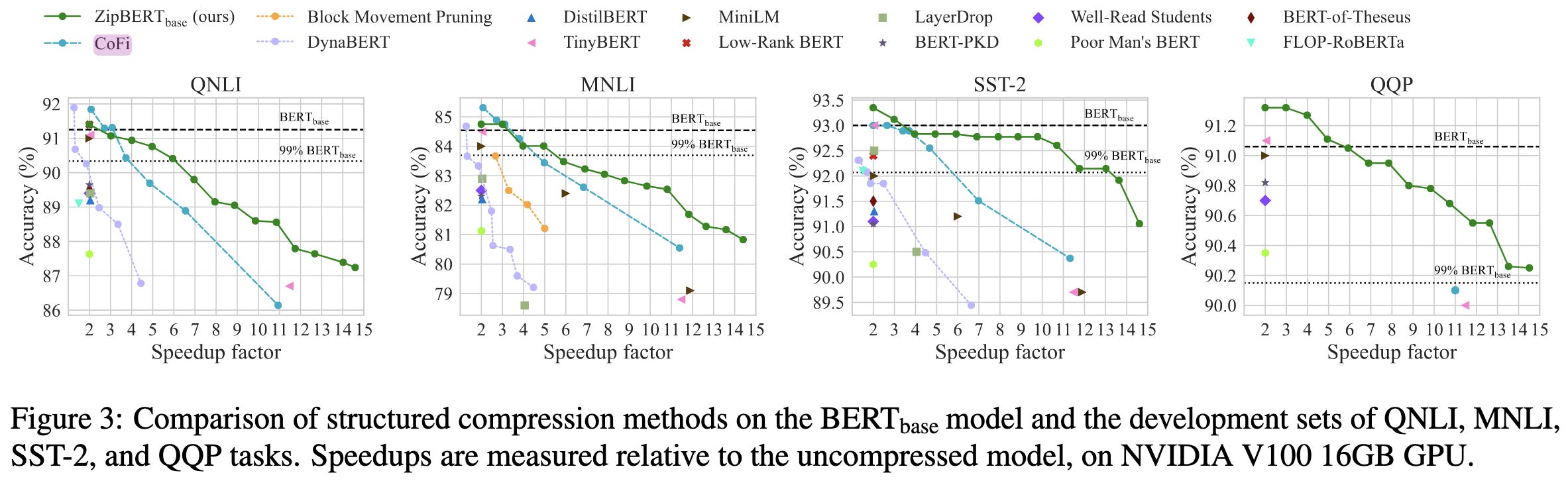
The basic approach is to prune gradually and incorporate knowledge of the hardware, including measured runtimes for different attention head counts and FFN shapes.

They also use a cyclic learning rate to deliver a whole family of models from one training run, with each cycle ending in a more aggressively pruned model.
The pruning decisions are based on examination of the inverse Hessian of the data and the current structure of the weight matrix—the idea is to remove rows/cols of the weights that minimally influence the predictions.

They recover accuracy by doing training the pruned model to preserve the dense model’s representations of each token across the layers.

They have a lot of wall time vs accuracy results with great numbers.



They also have some interesting results comparing altered model size vs altered pruning degree. Pruning with their method improves the tradeoff for large and small models, but there’s a switch between which you should use depending on target runtime. For moderate acceleration, you should use a larger model (consistent with other work); but for extreme acceleration, you should use a smaller model.

Strong evaluation and results with some interesting ideas.
ResMem: Learn what you can and memorize the rest
They propose to fit a neural net’s residuals with a KNN classifier/regressor, and use the two models together to make predictions.

This is as simple as it sounds, though the details are a bit coupled to classification with a softmax.

This can improve accuracy significantly on various tasks.

It seems to be most helpful for sufficiently large datasets and sufficiently small models.

It’s not clear whether this is a speed vs accuracy win, but I suspect it might be in many cases given the sheer accuracy lift. Plus it’s interesting that the method guarantees ~0 training loss—my inner statistical learning theorist is imagining all the cool guarantees we could get with that term zeroed out.
Blockwise Self-Supervised Learning at Scale
Can you split your network into chunks and just backprop through each chunk? If so, this would be amazing for pipeline parallelism.
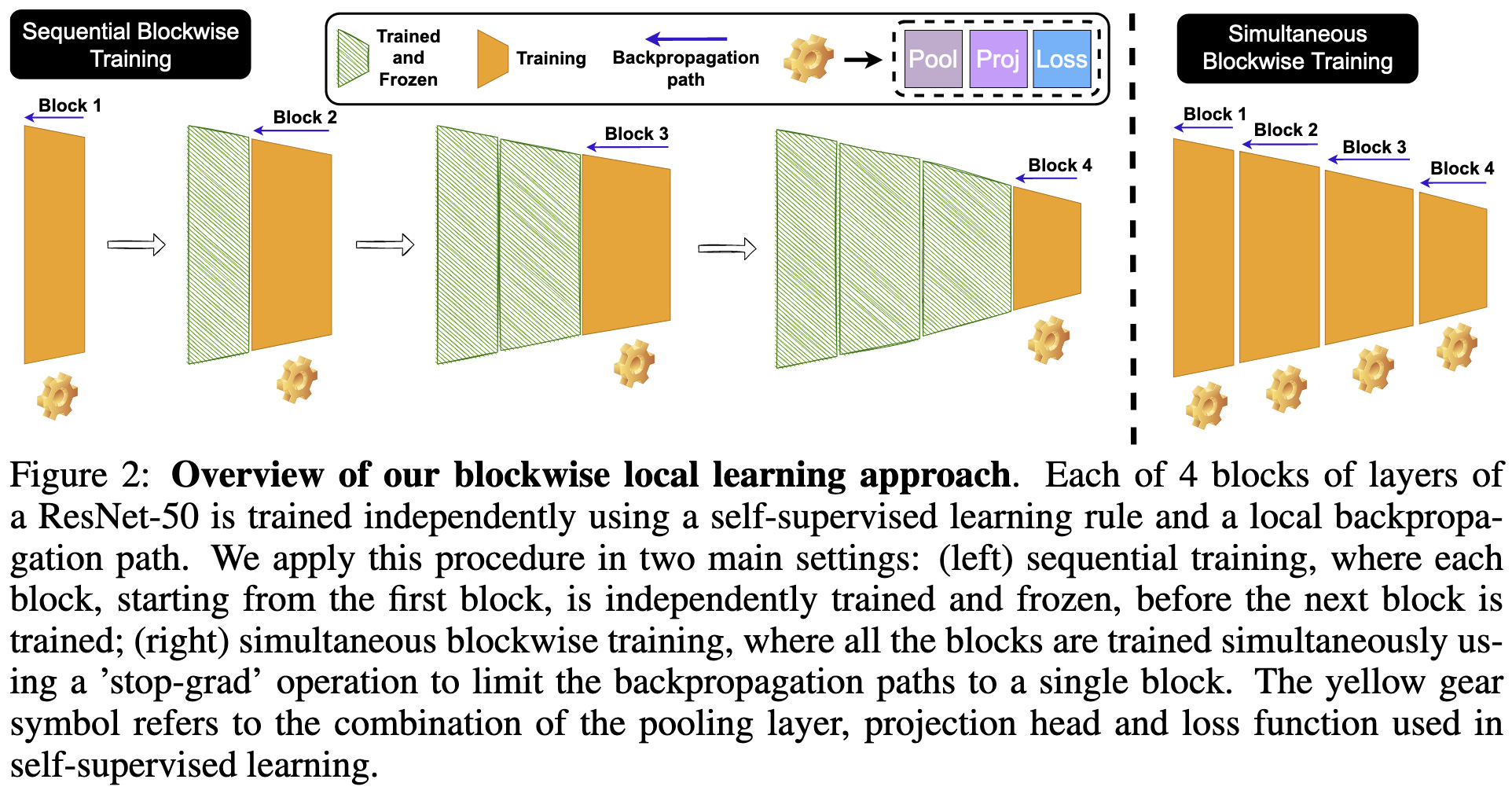
They find that they can get accuracy almost equal to that of end-to-end SSL training with blockwise SSL training, as long as they train all the blocks simultaneously, add some noise, and get the hparams right.


To deal with different blocks having different channel counts, they turn spatial size into channel count using conv-based expansion (CbE).

Promising results—at least for SSL workloads3, we might be approaching a world where pipeline parallelism is nearly free.
Diagnosing and Rectifying Vision Models using Language
Let’s say you have a multimodal model that:
Maps images and text to the same embedding space, and
Can apply an image classification head to the embeddings.
Then you can actually feed text into the image classifier and see how that affects the predictions. I.e., you embed the text using your text encoder and then just shove that embedding through the image classifier.

Feeding in text to probe model behavior is way easier than feeding in images, and lets you systematically identify failure modes and important features. If, e.g., the model thinks all birds are seagulls whenever the word “ocean” is in the text, it’s probably making that prediction based on the background rather than the animal itself.
Pretty cool—one of those things I’ve never thought of but that feels obvious in retrospect. As multimodal models become more common, I’d bet on variations of this seeing wide adoption.
Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery
There’s been a lot of work on prompt tuning, which typically means constructing optimized embeddings to feed into the model. But often we don’t want embeddings—we want regular text that a human can read, copy-paste, etc.

They propose an algorithm to construct text prompts by optimizing in the continuous embedding space but taking into account how it will be projected into the set of token embeddings.

This seems to yield effective prompts, but boy are they not what a human would come up with…


They also show how to distill longer prompts into shorter ones, with fairly good results. The shortest prompts tend to be concise and readable, while the intermediate-length ones often look crazy.

In an interesting ablation experiment, they find that you get the best eval CLIP scores with prompt lengths between 8 and 32 tokens.
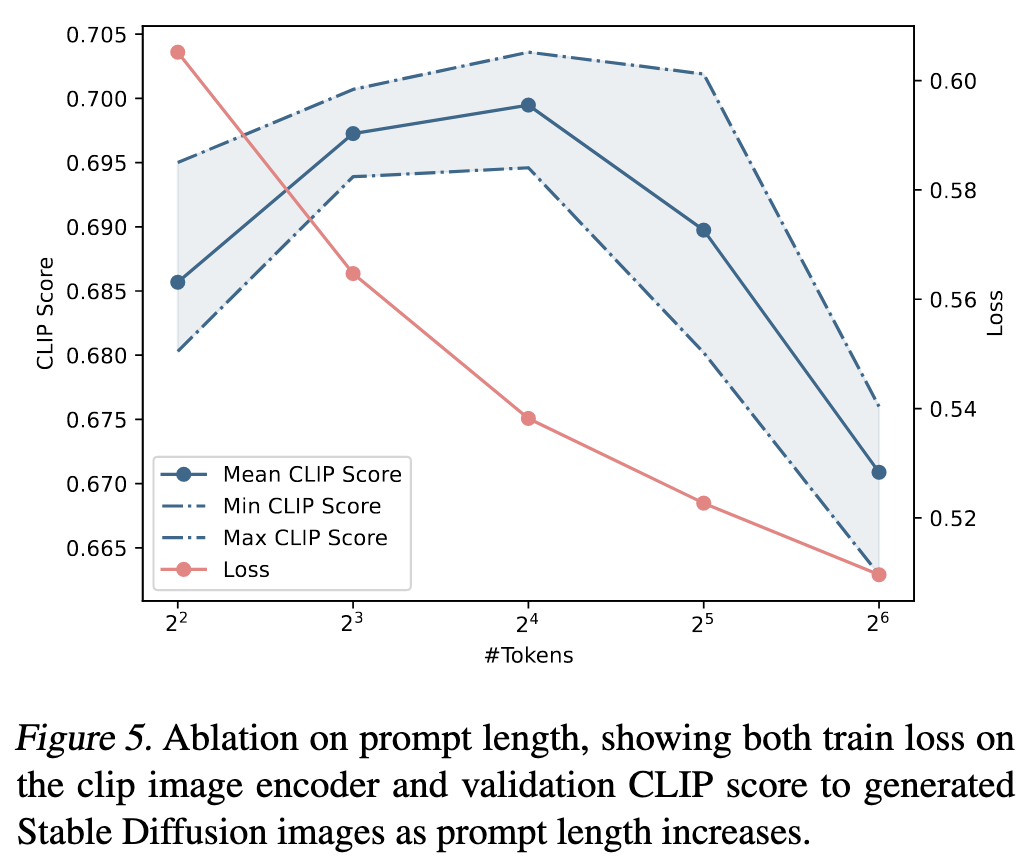
Seems like strong work on easing prompt engineering. It’s disconcerting that the most effective prompts often look like nonsense, but maybe this is just an artifact of the optimization process, rather than an intrinsic property of the model.
Toolformer: Language Models Can Teach Themselves to Use Tools
They trained a transformer to call external APIs; this entails not only figuring out which functions to call, but also what arguments to provide and how to use the outputs.

The basic approach is to add API calls as specially-formatted text into the training data. So as the model learns to predict the next token, it also learns to add in API calls.

As part of preparing the training data, they call the APIs and inject the results into the API-call block. In the below grammar, “r” is the API call result.

To add API call text into datasets at scale, they use a pretrained language model with a specific prompt. This model takes in original text and suggests places to inject API calls.

They use this strategy to teach models to use calculators, calendars, Wikipedia, and an external question answering model.

Allowing tool use often yields large accuracy gains. E.g., having a calculator helps a ton with mathematical reasoning.

Having models call external code makes a ton of sense, and this seems like a nice, clean way of making that happen.
GPTScore: Evaluate as You Desire
They use language models to evaluate the output of language models.

Concretely, they add the first model’s output into a templated prompt that asks the eval model whether the first model did a good job in various respects.

You can use this idea to assess tons of different aspects of a model.

Their method’s scores seems to correlate with human evaluations of text to some extent.

They also find that, unsurprisingly, their method does better when you include more demonstrations of good assessments in the prompt to the eval model.

Strong recursive self-improvement vibes from this one (and the previous paper). I used to think that we’d only be able to programmatically create infinite data for problems like coding, where you can check the solution. But work like this and Unnatural Instructions suggests that we might be able to get a positive feedback loop of increasingly good models generating increasingly large and clean datasets.
Quantized Distributed Training of Large Models with Convergence Guarantees
They added weight + gradient quantization to Zero-3 / FSDP. Basically you just quantize right before each time you communicate.

In more detail:
They quantize chunks of 1024 elements independently (to trade off speed and size vs narrow quantization ranges).
They only coalesce parameters within a module, not across modules like FSDP.
They don’t bother quantizing biases or other small parameter tensors.
They learn the quantization thresholds using gradient descent. The optimization happens periodically for each param/grad tensor after warmup.


This method has good theoretical guarantees, which roughly stem from viewing the quantized optimization as projected gradient descent and bounding the quantization-induced error.

When your interconnect is slow, this quantization can speed up training 2x or more. With 100Gbps rather than 10gbps, this drops to a 15% speedup though.

On the bright side, this speedup comes without any clear loss of model quality.

A nice, practical contribution that I’m sure was a huge pain to get working.
Scaling Vision Transformers to 22 Billion Parameters
They get large-scale vision transformer training to work well and investigate the benefits of scaling up.
First, they find that normalizing the query and key matrices in your transformer layers works wonders for stability.


They also confirm that running the attention and MLP blocks in parallel—rather than sequentially—works fine.
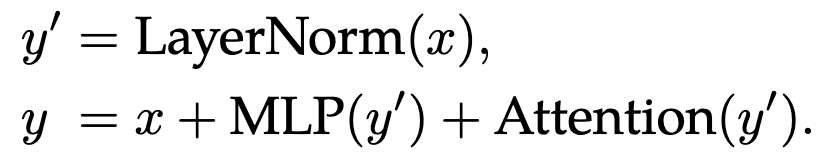
It took a bunch of work to set up the model sharding properly, even with `jax.xmap` doing a lot of the heavy lifting.

After training the model on 4 billion images from an internal Google dataset, they find that the larger scale helps compared to a smaller ViTs. It doesn’t help that much at high resolution though.

On out-of-distribution data, the larger model does about as well as you’d expect given its in-distribution accuracy. Another reproduction of the finding that IID and OOD accuracy often have a linear relationship.

Interestingly, their huge model doesn’t do better than a smaller model on semantic segmentation once the finetuning dataset is large enough.

Overall, it tends to work better than other vision models, but it doesn’t feel like a GPT-3 or ChatGPT situation where emergent capabilities make it seem like something out of a sci-fi movie. They also didn’t report any power law scaling, which might be because they didn’t observe it?
Fast Gumbel-Max Sketch and its Applications
They propose a 10x faster algorithm for sampling a batch of k elements from a categorical distribution, compared to the naive approach of just sampling them each using the Gumbel-max trick. A cool new tool for your algorithmic toolbox.

A Study on ReLU and Softmax in Transformer
Using a softmax in the attention mechanism causes a small number of values to dominate the attention, though layernorm can partially fix this. Using ReLU instead of softmax has more diffuse attention.

They suggest that this can make ReLU preferable to softmax in attention matrices when the sequences are long enough, since it allows more information to get through.
They also point out that FFNs can be cast as a form of key-value memory (especially with layernorm); unlike in self-attention, keys and values are learned constants rather than being computed on-the-fly from each input token.
Cliff-Learning
Sometimes finetuning learns faster than a power law, as indicated by the error dropping faster than a straight line on a log-log plot. Why does this happen?

One clue is that it takes place even in simple problems like linear regression.

So what does this mean? Well…it’s not clear. This seems to just be a workshop paper for now, but they conjecture that it might have something to do with having the initialization/regularization impose a suitable prior.
The Framework Tax: Disparities Between Inference Efficiency in Research and Deployment
FLOP count and inference latency aren’t as related as you might hope.

A lot of this stems from framework overhead, especially at small batch sizes.


Not super surprising, but great to see the problem so thoroughly characterized.
How to Use Dropout Correctly on Residual Networks with Batch Normalization
Through a bunch of math and experiments, they find that you should:
Apply dropout after the last batchnorm in your ResNet block, but before the last conv (position P5 or P6, below)

At the end of the ResNet, apply dropout right before the global average pool (position H3 or H4, below).
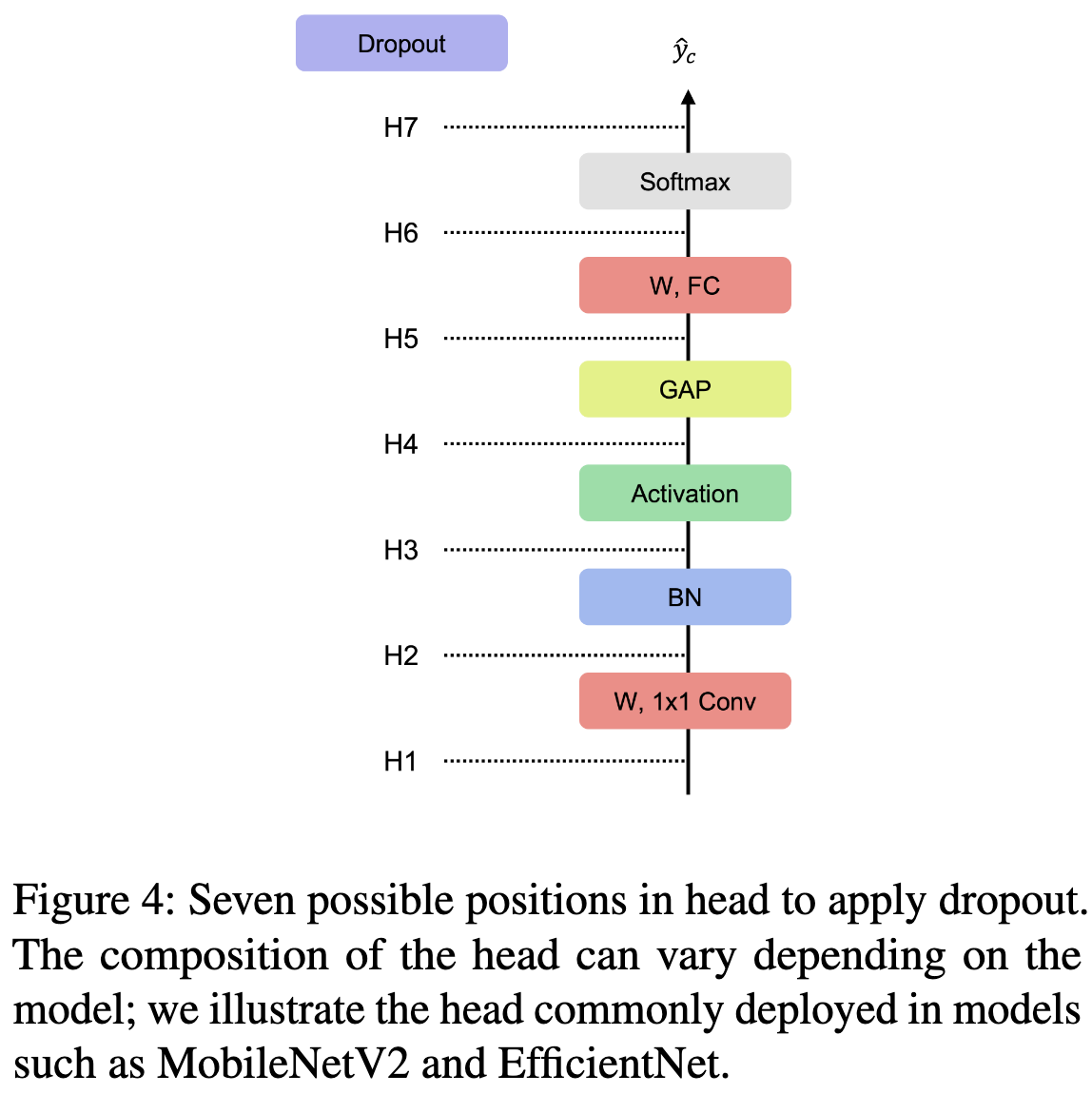


At least for ResNets doing image classification, this seems to improve accuracy a little bit.


Decoupled Model Schedule for Deep Learning Training
AWS built a library for model optimization, including intra-device optimizations, distributed scheduling, and training support.
Mostly, this paper has some of the clearest explanations I’ve seen of:
Layer fusion

Swapping in efficient kernels

And adding tensor parallelism.




Their system seems to help a little bit vs torchscript and vanilla eager execution,

as well as vs. their Megatron and DeepSpeed baselines.

Big Little Transformer Decoder
They use a big language model to correct the outputs of a small language model. The small language model has to produce tokens sequentially, while the big model can process tokens in parallel to get better compute utilization.
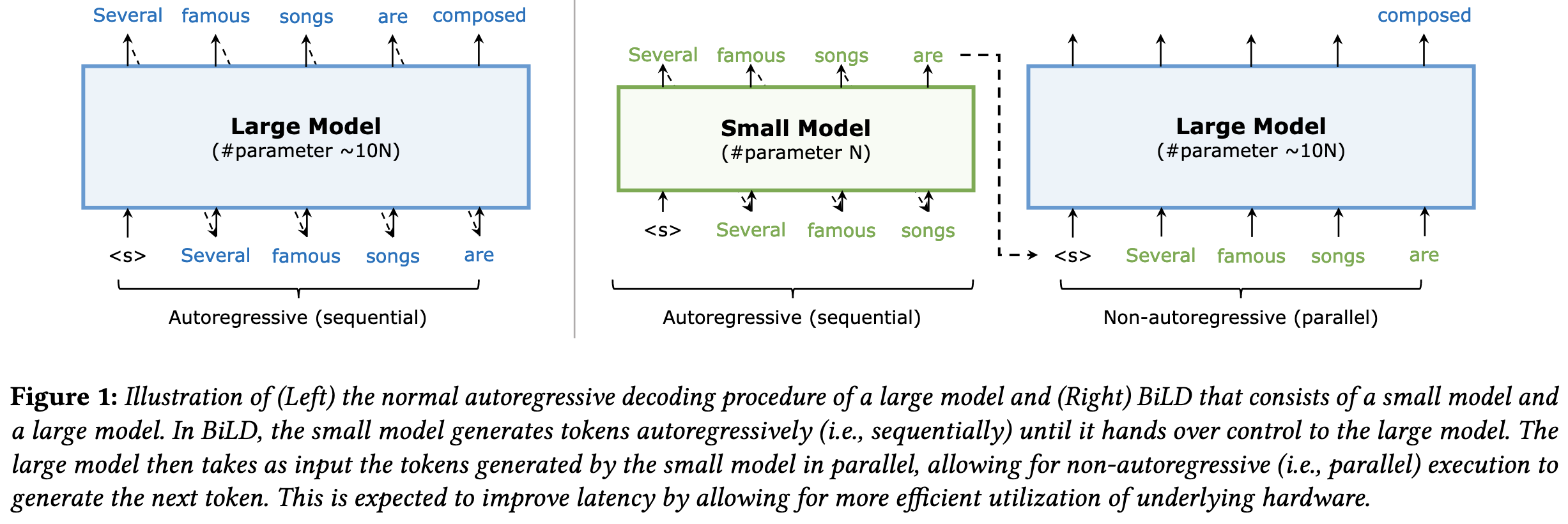
In more detail, the small model invokes the large model whenever one of the former’s predicted tokens has too low a probability. The big model then makes predictions for the whole sequence so far. If the big model disagrees with any of the previous predictions too strongly, we throw away all the text from the first point of disagreement and generate fresh tokens from that point on. The idea is that, once the small model has gone off the rails, we ignore the rest of its output and try again.


This approach can improve the tradeoff between average inference latency and various quality metrics.

Always nice to see a real, wall-time efficiency improvement.
In fact, GCC and Clang will turn vectorize-able groups of xnor + popcount instructions (binary dot products) into shufb instructions (table lookups).
Vector quantization support is the purest hardware lottery example I’m aware of.
Stronger conjecture: almost all training workloads will be SSL, at least for all but the last few layers of the network.
Hey Davis. I saw that you were recommended by the Gradient. I went through your content, and it is amazing. It looks like we're both involved in the same fields. I'd love to collaboate with you. My Substack, AI Made Simple, has over 10K Readers and is also recommended by Gradient (and a few others). Let me know if you would be open to it.
https://artificialintelligencemadesimple.substack.com/